文章目录
前面我们学习了用自定义的方式来对 Kubernetes 集群进行监控,但是还是有一些缺陷,比如 Prometheus、AlertManager 这些组件服务本身的高可用。当然我们也完全可以用自定义的方式来实现这些需求,Promethues 在代码上就已经对 Kubernetes 有了原生的支持,可以通过服务发现的形式来自动监控集群,因此我们可以使用另外一种更加高级的方式来部署 Prometheus:Kube-Prometheus(Operator) 框架。
1、什么是Kube-Prometheus(Operator) 框架
Operator是由 CoreOS 公司开发的,用来扩展 Kubernetes API,特定的应用程序控制器。它被用来创建、配置和管理复杂的有状态应用,如数据库、缓存和监控系统。Operator 是基于 Kubernetes 的资源和控制器概念之上构建,但同时又包含了应用程序特定的一些专业知识:比如创建一个数据库的Operator,则必须对创建的数据库的各种运维方式非常了解,创建Operator的关键是CRD(自定义资源)的设计。
注:CRD是对 Kubernetes API 的扩展,Kubernetes 中的每个资源都是一个 API 对象的集合,例如我们在 YAML文件里定义的那些spec都是对 Kubernetes 中的资源对象的定义,所有的自定义资源可以跟 Kubernetes 中内建的资源一样使用 kubectl 操作。
Operator是将运维人员对软件操作的知识给代码化,同时利用 Kubernetes 强大的抽象来管理大规模的软件应用。目前CoreOS官方提供了几种Operator的实现,其中就包括我们今天的主角:Prometheus Operator,Operator的核心实现就是基于 Kubernetes 的以下两个概念:
- 资源:对象的状态定义;
- 控制器:观测、分析和行动,以调节资源的分布。
在最新的版本中,Kubernetes的 Prometheus-Operator 部署内容已经从 Prometheus-Operator 的 Github工程中拆分出独立工程Kube-Prometheus。Kube-Prometheus 即是通过 Operator 方式部署的Kubernetes集群监控,所以我们直接容器化部署 Kube-Prometheus 即可。
Kube-Prometheus项目地址:https://github.com/coreos/kube-prometheus
因为我们前面Kubernetes集群的安装版本为v1.16.8,为了考虑兼容性、这里我们安装 Kube-Prometheus-Release-0.4 版本。当然大家也可以去 Kube-Prometheus 的文档中查看兼容性列表,如下:

注:关于 Kube-Prometheus 更多的介绍内容、大家可以移步官方文档详细查看。
2、Kube-Prometheus部署
2.1、Kube-Prometheus安装
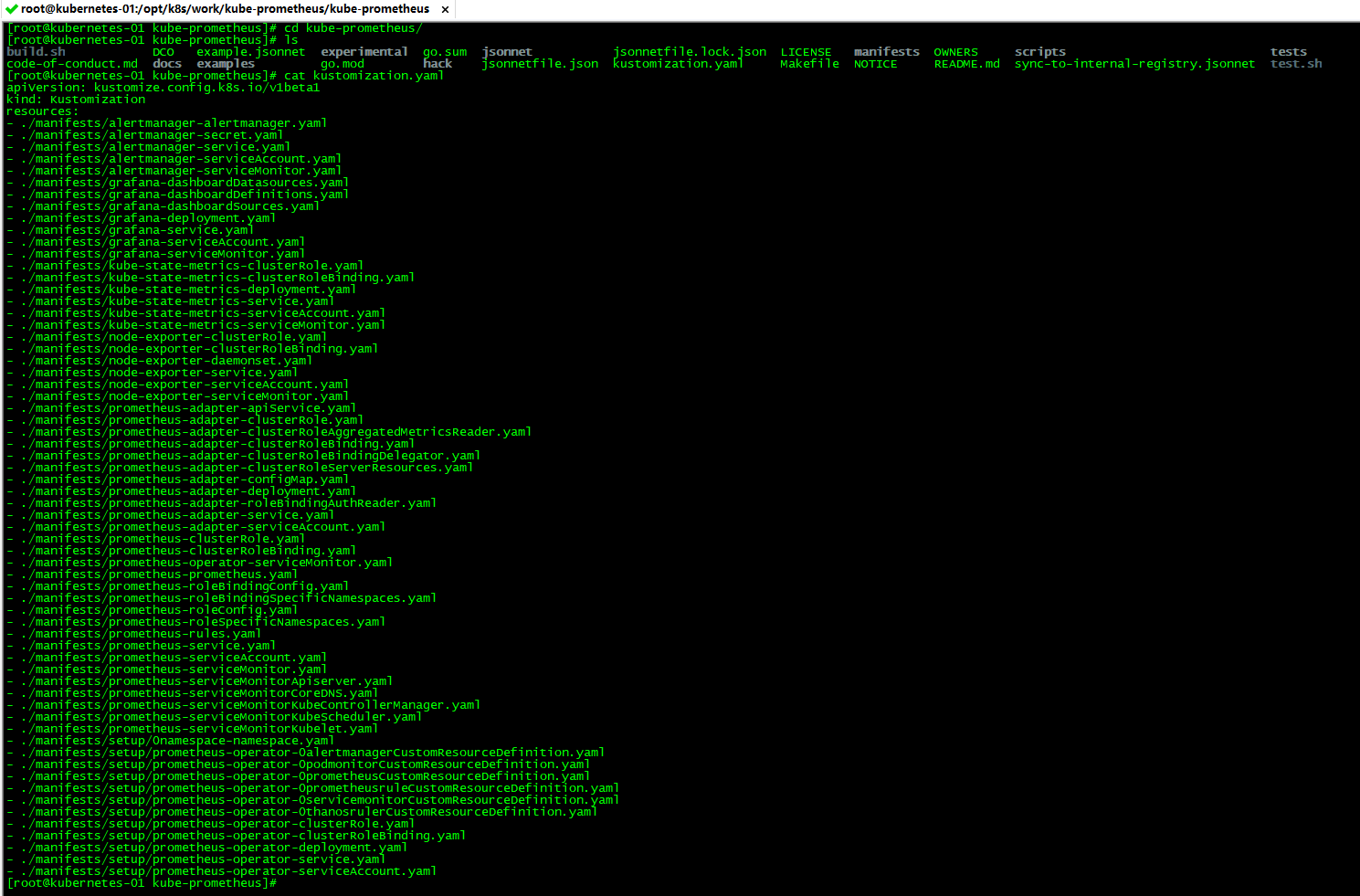
下面我们直接开始部署Kube-Prometheus,我们通过 git clone 命令把项目下载到本地以后,直接进入 Kube-Prometheus 根目录,根目录下面的 kustomization.yaml 文件中包含了所有相关的容器化配置文件:
# 这里我们下载0.4版本
git clone https://github.com/coreos/kube-prometheus.git
cd kube-prometheus
cat kustomization.yaml
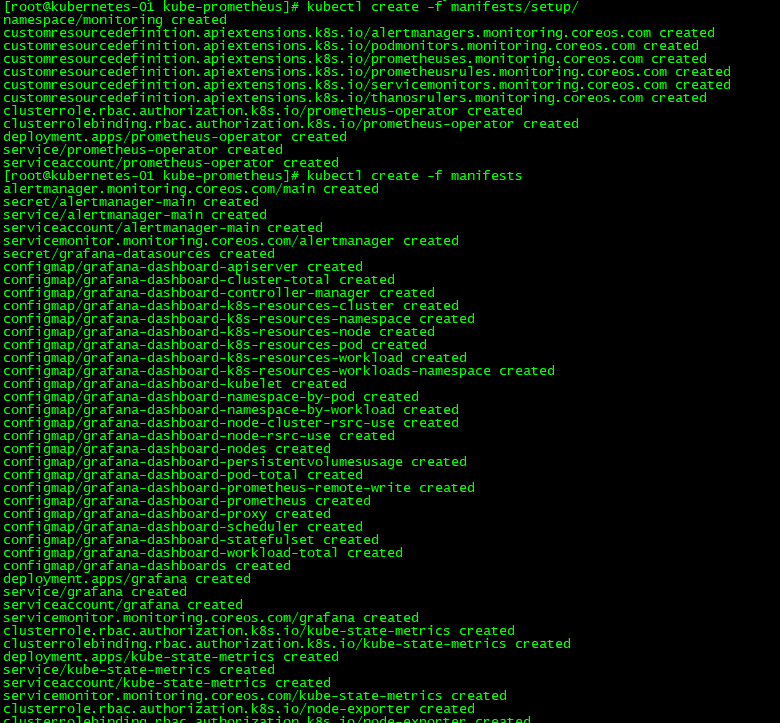
这里我们直接依次执行下面的命令即可完成安装:
kubectl create -f manifests/setup
kubectl create -f manifests
部署完成后,会创建一个名为monitoring的 namespace,所以资源对象对将部署在改命名空间下面,此外 Operator 会自动创建6个 CRD 资源对象:

我们可以在 monitoring 命名空间下面查看所有的 Pod和SVC资源,其中 alertmanager 和 prometheus 是用 StatefulSet 控制器管理的,其中还有一个比较核心的 prometheus-operator 的 Pod,用来控制其他资源对象和监听对象变化的:
kubectl get pod -n monitoring -o wide
kubectl get svc -n monitoring -o wide

可以看到上面针对 grafana 和 prometheus 都创建了一个类型为 ClusterIP 的 Service,这里我们还是采用 Traefik Ingress 的方式来暴露 grafana 和 prometheus 服务:
grafana-route.yaml:
apiVersion: traefik.containo.us/v1alpha1
kind: IngressRoute
metadata:
name: grafana
namespace: monitoring
spec:
entryPoints:
- web
routes:
- match: Host(`grafana.z0ukun.com`)
kind: Rule
services:
- name: grafana
namespace: monitoring
port: 3000
prometheus-route.yaml:
apiVersion: traefik.containo.us/v1alpha1
kind: IngressRoute
metadata:
name: prometheus-k8s
namespace: monitoring
spec:
entryPoints:
- web
routes:
- match: Host(`prom.z0ukun.com`)
kind: Rule
services:
- name: prometheus-k8s
namespace: monitoring
port: 9090
我们直接创建上面两个Ingress资源对象,创建完成以后我们就可以在 Traefik 面板看到相应规则;我们直接修改 hosts 文件,然后通过 grafana.z0ukun.com 和 prom.z0ukun.com 域名访问相关服务,比如查看 Prometheus 的 targets 页面:
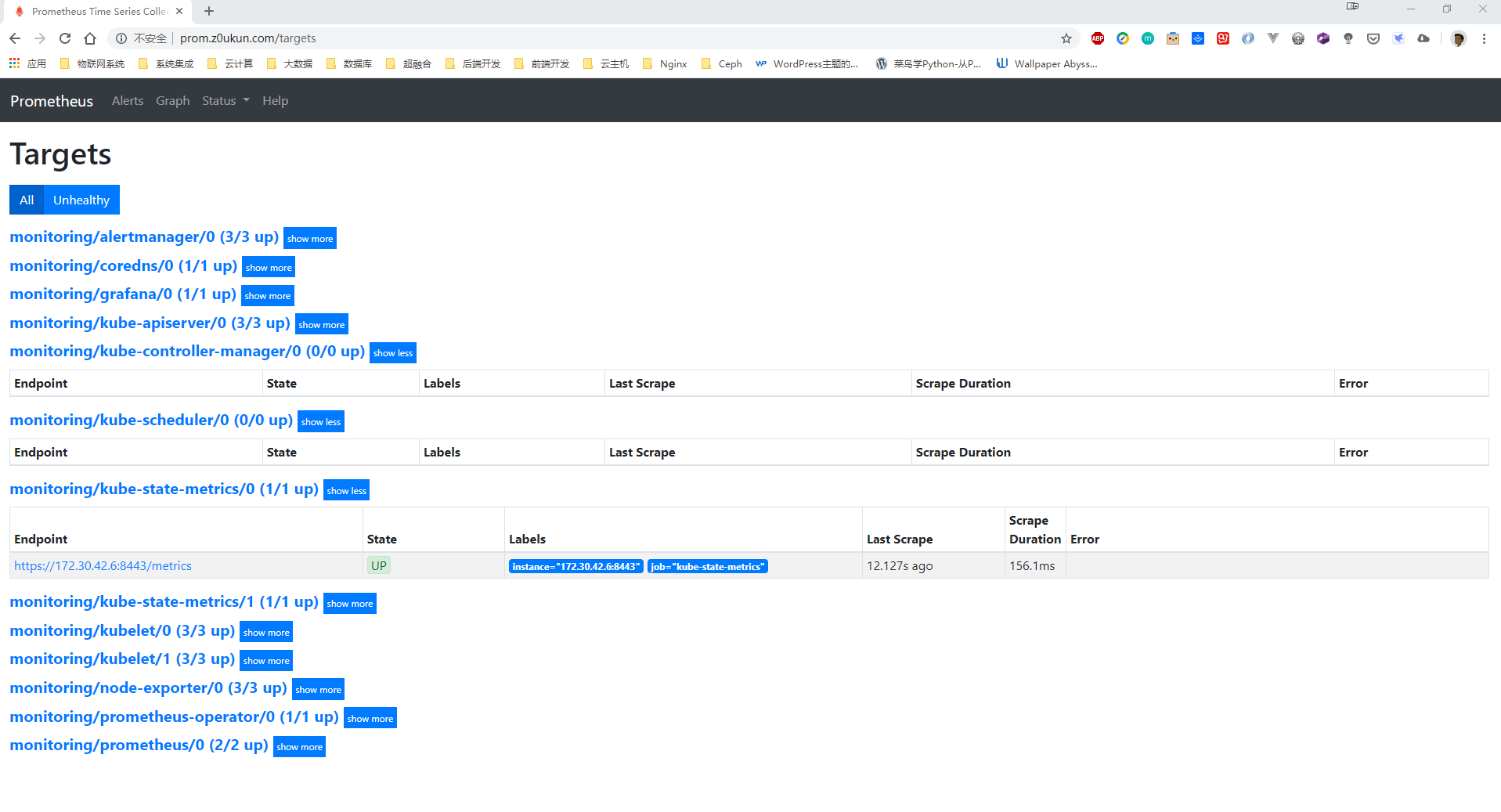
注:如果服务状态有问题的同学请自行通过describe和logs命令排查故障(记得提前拉取相关镜像)。没有部署Ingress的同学也可以将服务类型更改为 NodePort,这里就不再过多介绍了。
2.2、Kube-Prometheus配置
我们可以看到大部分的配置都是正常的,只有两个没有管理到对应的监控目标,比如 kube-controller-manager 和 kube-scheduler 这两个系统组件,这就和 ServiceMonitor 的定义有关系了,我们先来查看下 kube-scheduler 组件对应的 ServiceMonitor 资源的定义(prometheus-serviceMonitorKubeScheduler.yaml):
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
k8s-app: kube-scheduler
name: kube-scheduler
namespace: kube-system
spec:
endpoints:
- interval: 30s # 每30s获取一次信息
port: http-metrics # 对应service的端口名
jobLabel: k8s-app
namespaceSelector: # 表示去匹配某一命名空间中的service,如果想从所有的namespace中匹配用any: true
matchNames:
- kube-system
selector: # 匹配的 Service 的labels,如果使用mathLabels,则下面的所有标签都匹配时才会匹配该service,如果使用matchExpressions,则至少匹配一个标签的service都会被选择
matchLabels:
k8s-app: kube-scheduler
上面是一个典型的 ServiceMonitor 资源文件的声明方式,上面我们通过selector.matchLabels在 kube-system 这个命名空间下面匹配具有k8s-app=kube-scheduler这样的 Service,但是我们系统中根本就没有对应的 Service,所以我们需要手动创建一个 Service(prometheus-kubeSchedulerService.yaml):
apiVersion: v1
kind: Service
metadata:
namespace: kube-system
name: kube-scheduler
labels:
k8s-app: kube-scheduler
spec:
#selector:
# component: kube-scheduler
ports:
- name: http-metrics
port: 10251
targetPort: 10251
protocol: TCP
我们采用相同的方法创建Kube-Controller-Manager的ServiceMonitor和Service资源:
prometheus-serviceMonitorKubeControllerManager.yaml:
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
k8s-app: kube-controller-manager
name: kube-controller-manager
namespace: kube-system
spec:
endpoints:
- interval: 30s
port: http-metrics
jobLabel: k8s-app
namespaceSelector:
matchNames:
- kube-system
selector:
matchLabels:
k8s-app: kube-controller-manager
prometheus-KubeControllerManagerService.yaml:
apiVersion: v1
kind: Service
metadata:
namespace: kube-system
name: kube-controller-manager
labels:
k8s-app: kube-controller-manager
spec:
#selector:
# component: kube-controller-manager
ports:
- name: https-metrics
port: 10252
targetPort: 10252
protocol: TCP
创建完成之后我们通过 kubectl get svc -n kube-system 命令看到对应SVC资源已经生成了:
kubectl get svc -n kube-system

但是此时Prometheus面板的 targets 还是没有任何显示,我们通过 kubectl get ep -n kube-system 命令去查看一下 kube-controller-manager 和 kube-scheduler 的endpoints发现并没有任何endpoints,这里我们需要手动来添加endpoints。我们定义两个endpoints资源文件,如下:
kubectl get ep -n kube-system

prometheus-kubeSchedulerServiceEnpoints.yaml
apiVersion: v1
kind: Endpoints
metadata:
labels:
k8s-app: kube-scheduler
name: kube-scheduler
namespace: kube-system
subsets:
- addresses:
- ip: 172.16.200.11
- ip: 172.16.200.12
- ip: 172.16.200.13
ports:
- name: http-metrics
port: 10251
protocol: TCP
prometheus-KubeControllerManagerServiceEnpoints.yaml
apiVersion: v1
kind: Endpoints
metadata:
labels:
k8s-app: kube-controller-manager
name: kube-controller-manager
namespace: kube-system
subsets:
- addresses:
- ip: 172.16.200.11
- ip: 172.16.200.12
- ip: 172.16.200.13
ports:
- name: https-metrics
port: 10252
protocol: TCP
定义完成之后我们直接去创建上面的两个endpoints资源,然后我们继续查看 kube-controller-manager 和 kube-scheduler 的endpoints资源状态:
kubectl get ep -n kube-system

我们已经成功为 kube-controller-manager 和 kube-scheduler 这两个SVC资源添加了 Endpoints 资源。但是此时我们去刷新Prometheus的 target 可以看到 monitoring/kube-scheduler/0 数据正常、但是 monitoring/kube-controller-manager/0 状态显示为DOWN。错误信息为:Server Returned HTTP Status 400 Bad Request。仔细观察我们会发现、Endpoints 信息为:http://172.16.200.11:10252/metrics,我们在前面部署 kube-controller-manager 明明用的是HTTPS、但是为什么这里就变成 HTTP 了呢?
我们去查看 prometheus-serviceMonitorKubeControllerManager.yaml 文件发现 kube-controller-manager 的 ServiceMonitor kind 端口写的是 http-metrics。我们需要把Port修改为https-metrics,并添加token信息,这里我们可以 insecureSkipVerify: true 参数禁止掉证书验证,详细信息如下:
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
k8s-app: kube-controller-manager
name: kube-controller-manager
namespace: kube-system
spec:
endpoints:
- bearerTokenFile: /var/run/secrets/kubernetes.io/serviceaccount/token # 添加token
interval: 30s
metricRelabelings:
- action: drop
regex: kubelet_(pod_worker_latency_microseconds|pod_start_latency_microseconds|cgroup_manager_latency_microseconds|pod_worker_start_latency_microseconds|pleg_relist_latency_microseconds|pleg_relist_interval_microseconds|runtime_operations|runtime_operations_latency_microseconds|runtime_operations_errors|eviction_stats_age_microseconds|device_plugin_registration_count|device_plugin_alloc_latency_microseconds|network_plugin_operations_latency_microseconds)
sourceLabels:
- __name__
- action: drop
regex: scheduler_(e2e_scheduling_latency_microseconds|scheduling_algorithm_predicate_evaluation|scheduling_algorithm_priority_evaluation|scheduling_algorithm_preemption_evaluation|scheduling_algorithm_latency_microseconds|binding_latency_microseconds|scheduling_latency_seconds)
sourceLabels:
- __name__
- action: drop
regex: apiserver_(request_count|request_latencies|request_latencies_summary|dropped_requests|storage_data_key_generation_latencies_microseconds|storage_transformation_failures_total|storage_transformation_latencies_microseconds|proxy_tunnel_sync_latency_secs)
sourceLabels:
- __name__
- action: drop
regex: kubelet_docker_(operations|operations_latency_microseconds|operations_errors|operations_timeout)
sourceLabels:
- __name__
- action: drop
regex: reflector_(items_per_list|items_per_watch|list_duration_seconds|lists_total|short_watches_total|watch_duration_seconds|watches_total)
sourceLabels:
- __name__
- action: drop
regex: etcd_(helper_cache_hit_count|helper_cache_miss_count|helper_cache_entry_count|request_cache_get_latencies_summary|request_cache_add_latencies_summary|request_latencies_summary)
sourceLabels:
- __name__
- action: drop
regex: transformation_(transformation_latencies_microseconds|failures_total)
sourceLabels:
- __name__
- action: drop
regex: (admission_quota_controller_adds|crd_autoregistration_controller_work_duration|APIServiceOpenAPIAggregationControllerQueue1_adds|AvailableConditionController_retries|crd_openapi_controller_unfinished_work_seconds|APIServiceRegistrationController_retries|admission_quota_controller_longest_running_processor_microseconds|crdEstablishing_longest_running_processor_microseconds|crdEstablishing_unfinished_work_seconds|crd_openapi_controller_adds|crd_autoregistration_controller_retries|crd_finalizer_queue_latency|AvailableConditionController_work_duration|non_structural_schema_condition_controller_depth|crd_autoregistration_controller_unfinished_work_seconds|AvailableConditionController_adds|DiscoveryController_longest_running_processor_microseconds|autoregister_queue_latency|crd_autoregistration_controller_adds|non_structural_schema_condition_controller_work_duration|APIServiceRegistrationController_adds|crd_finalizer_work_duration|crd_naming_condition_controller_unfinished_work_seconds|crd_openapi_controller_longest_running_processor_microseconds|DiscoveryController_adds|crd_autoregistration_controller_longest_running_processor_microseconds|autoregister_unfinished_work_seconds|crd_naming_condition_controller_queue_latency|crd_naming_condition_controller_retries|non_structural_schema_condition_controller_queue_latency|crd_naming_condition_controller_depth|AvailableConditionController_longest_running_processor_microseconds|crdEstablishing_depth|crd_finalizer_longest_running_processor_microseconds|crd_naming_condition_controller_adds|APIServiceOpenAPIAggregationControllerQueue1_longest_running_processor_microseconds|DiscoveryController_queue_latency|DiscoveryController_unfinished_work_seconds|crd_openapi_controller_depth|APIServiceOpenAPIAggregationControllerQueue1_queue_latency|APIServiceOpenAPIAggregationControllerQueue1_unfinished_work_seconds|DiscoveryController_work_duration|autoregister_adds|crd_autoregistration_controller_queue_latency|crd_finalizer_retries|AvailableConditionController_unfinished_work_seconds|autoregister_longest_running_processor_microseconds|non_structural_schema_condition_controller_unfinished_work_seconds|APIServiceOpenAPIAggregationControllerQueue1_depth|AvailableConditionController_depth|DiscoveryController_retries|admission_quota_controller_depth|crdEstablishing_adds|APIServiceOpenAPIAggregationControllerQueue1_retries|crdEstablishing_queue_latency|non_structural_schema_condition_controller_longest_running_processor_microseconds|autoregister_work_duration|crd_openapi_controller_retries|APIServiceRegistrationController_work_duration|crdEstablishing_work_duration|crd_finalizer_adds|crd_finalizer_depth|crd_openapi_controller_queue_latency|APIServiceOpenAPIAggregationControllerQueue1_work_duration|APIServiceRegistrationController_queue_latency|crd_autoregistration_controller_depth|AvailableConditionController_queue_latency|admission_quota_controller_queue_latency|crd_naming_condition_controller_work_duration|crd_openapi_controller_work_duration|DiscoveryController_depth|crd_naming_condition_controller_longest_running_processor_microseconds|APIServiceRegistrationController_depth|APIServiceRegistrationController_longest_running_processor_microseconds|crd_finalizer_unfinished_work_seconds|crdEstablishing_retries|admission_quota_controller_unfinished_work_seconds|non_structural_schema_condition_controller_adds|APIServiceRegistrationController_unfinished_work_seconds|admission_quota_controller_work_duration|autoregister_depth|autoregister_retries|kubeproxy_sync_proxy_rules_latency_microseconds|rest_client_request_latency_seconds|non_structural_schema_condition_controller_retries)
sourceLabels:
- __name__
- action: drop
regex: etcd_(debugging|disk|request|server).*
sourceLabels:
- __name__
port: https-metrics # 把默认http-metrics修改为https-metrics
scheme: https # 添加https
tlsConfig:
insecureSkipVerify: true # 禁止验证证书信息
jobLabel: k8s-app
namespaceSelector:
matchNames:
- kube-system
selector:
matchLabels:
k8s-app: kube-controller-manager
我们直接通过 kubectl apply -f prometheus-serviceMonitorKubeControllerManager.yaml 更新上面的资源文件,然后稍等30秒重新刷新 prometheus 页面。我们可以看到 monitoring/kube-controller-manager/0 这个 target 状态已经变成UP了。这时我们去看看 Grafana 里面是否有对应数据,当然你也可以通过 PromSQL 来查询验证:
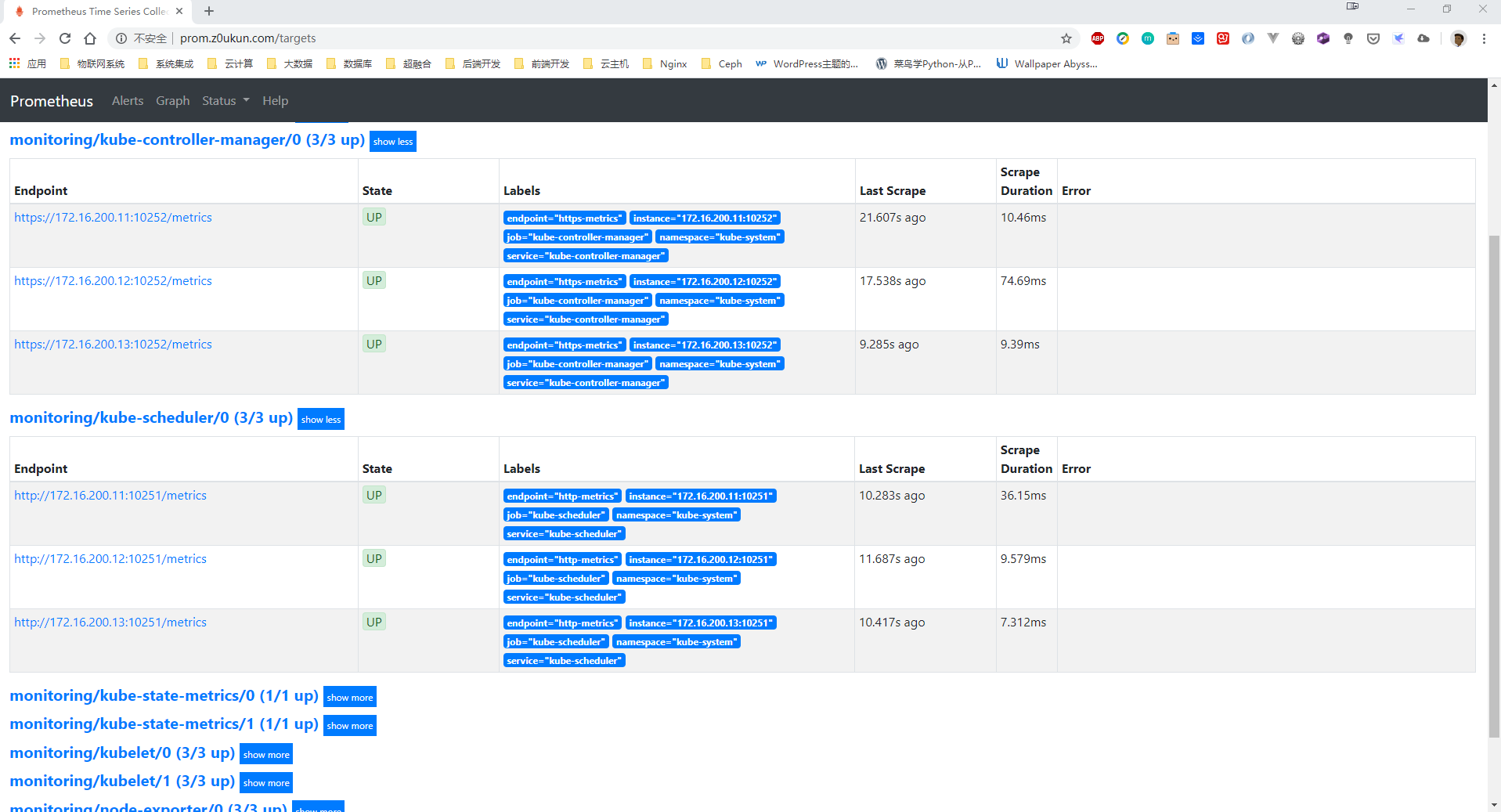
上面的监控数据配置完成后,现在我们可以去查看下 Grafana 下面的 Dashboard,我们使用上面配置的Ingress域名访问即可,第一次登录使用 admin:admin 登录即可,进入首页后,可以发现已经和我们的 Prometheus 数据源关联上了,正常来说可以看到一些监控图表了: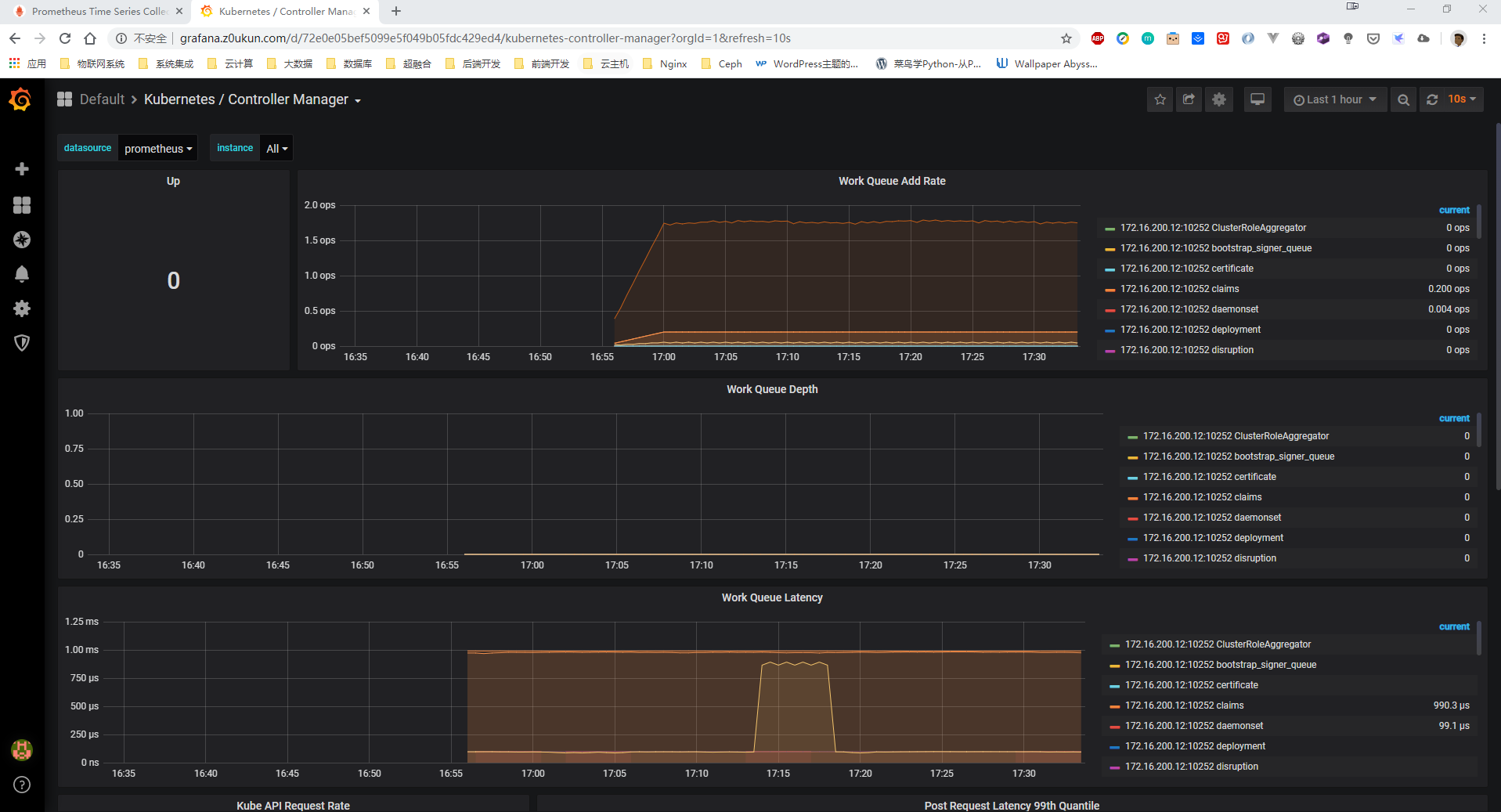

3、自定义 Kube-Prometheus 监控项
前面我们讲解了 如何快速部署 Kube-Prometheus 监控系统,下面我们继续介绍如何在 Kube-Prometheus 中添加一个自定义的监控项。除了 Kubernetes 集群中的一些资源对象、节点以及组件需要监控,有的时候我们可能还需要根据实际的业务需求去添加自定义的监控项,添加一个自定义监控的步骤也是非常简单的。
- 第一步:建立一个 ServiceMonitor 对象,用于 Prometheus 添加监控项;
- 第二步:为 ServiceMonitor 对象关联 metrics 数据接口的一个 Service 对象;
- 第三步:确保 Service 对象可以正确获取到 metrics 数据。
接下来我们就来看看如何添加 Etcd 集群的监控。无论是 Kubernetes 集群外的还是使用 Kubeadm 安装在集群内部的 Etcd 集群,我们这里都将其视作集群外的独立集群,因为对于二者的使用方法没什么特殊之处。
3.1、获取ETCD证书
对于 Etcd 集群,在搭建的时候我们就采用了https证书认证的方式,所以这里如果想用 Kube-Prometheus 访问到 Etcd 集群的监控数据,就需要添加证书。我们可以通过 systemctl status etcd 查看证书路径:
systemctl status etcd
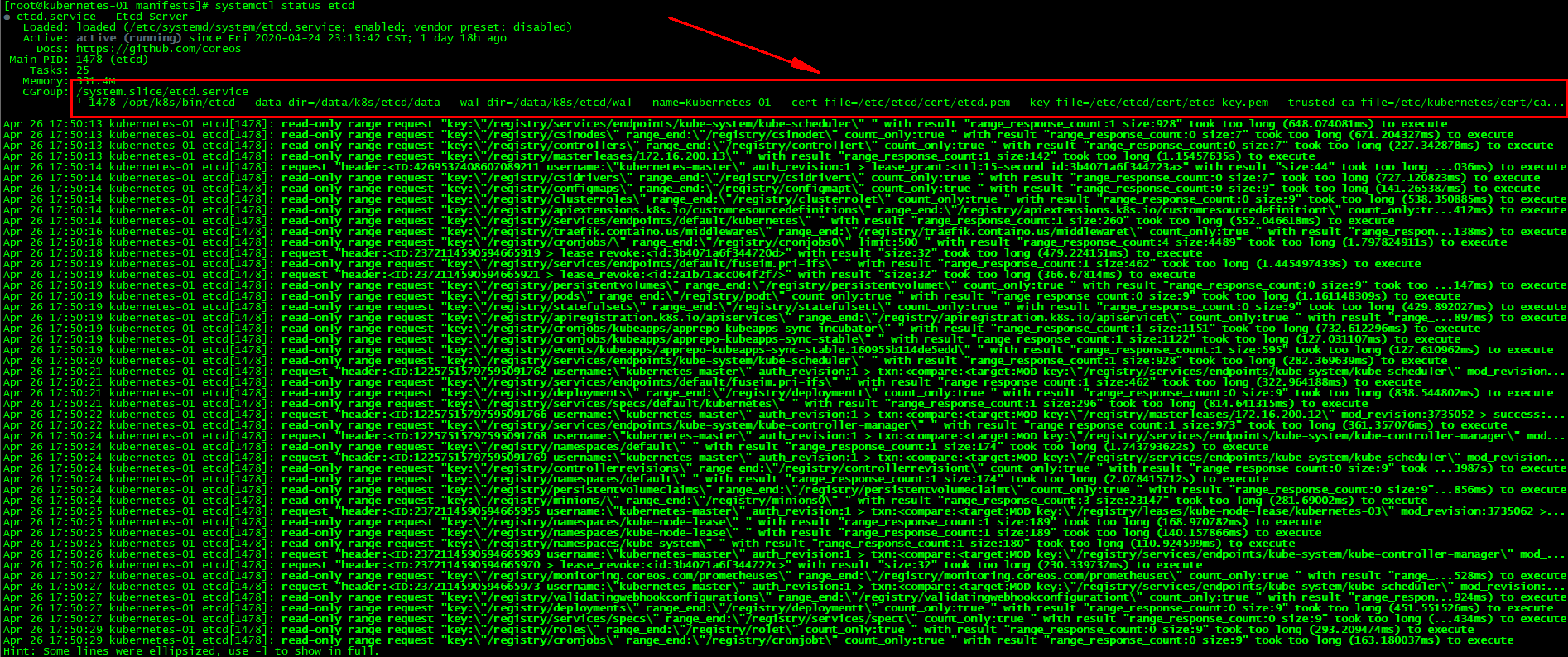
接下来我们通过启动文件,查看ETCD证书路径:
cat /etc/systemd/system/etcd.service
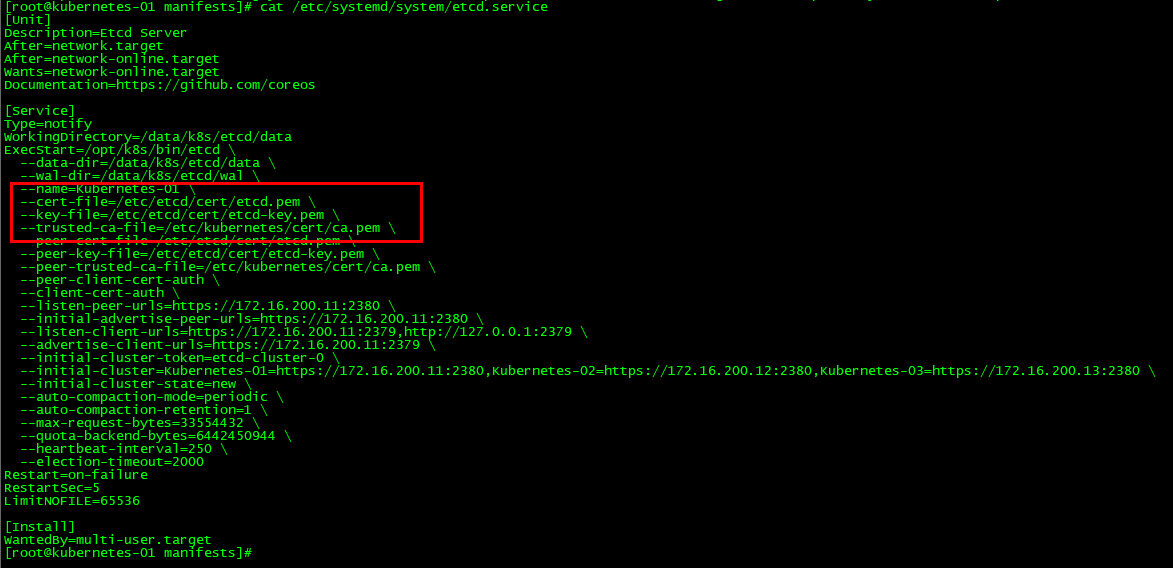
注:这里我查阅了很多资料、发现大部分都是基于 Kubeadm 的监控;而这里我是针对 Kubernetes 二进制搭建的监控。基于 Kubeadm 这里就不再详细描述了、请大家自行百度。
接下来我们需要创建一个 secret,让 Kube-Prometheus pod 节点挂载:
kubectl create secret generic etcd-ssl --from-file=/etc/kubernetes/cert/ca.pem --from-file=/etc/etcd/cert/etcd.pem --from-file=/etc/etcd/cert/etcd-key.pem -n monitoring
创建完完成以后我们可以通过下面的命令来检查一下:
kubectl describe secrets -n monitoring etcd-ssl

我们可以看到证书已经创建成功,然后我们将 etcd-ssl secret 对象配置到 Kube-Prometheus 资源对象中。这里我们可以通过 edit 命令直接编辑 Kube-Prometheus 或者 修改 prometheus-prometheus.yaml 文件,然后更新:
# 通过 edit 命令直接编辑
kubectl edit prometheus k8s -n monitoring
# 修改 prometheus-prometheus.yaml 文件
vim kube-prometheus-master/manifests/prometheus-prometheus.yaml
这里我们直接修改 prometheus-prometheus.yaml 资源文件,并添加内容如下:
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
......
replicas: 2
secrets:
- etcd-ssl# 添加secret名称
......
修改完成之后我们直接更新上面的资源文件,然后我们就可以在 Kube-Prometheus pod 中查看到对象的目录了:
# 更新资源文件
kubectl apply -f prometheus-prometheus.yaml
# 查看pod状态
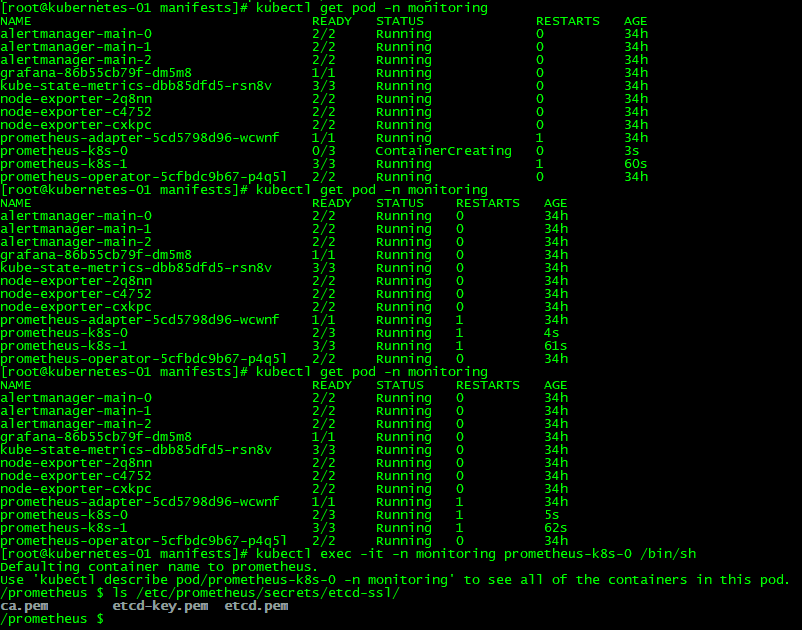
kubectl get pod -n monitoring
# 进入prometheus-k8s-0 Pod中
kubectl exec -it -n monitoring prometheus-k8s-0 /bin/sh
# 查看证书
ls /etc/prometheus/secrets/etcd-ssl/
3.2、创建ServiceMonitor
前面Kube-Prometheus已经挂载了ETCD证书文件,下面我们就可以直接来创建ServiceMonitor了:
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: etcd-k8s
namespace: monitoring
labels:
k8s-app: etcd-k8s
spec:
jobLabel: k8s-app
endpoints:
- port: port
interval: 30s
scheme: https
tlsConfig:
caFile: /etc/prometheus/secrets/etcd-ssl/ca.pem #证书路径 (Pod里的路径)
certFile: /etc/prometheus/secrets/etcd-ssl/etcd.pem
keyFile: /etc/prometheus/secrets/etcd-ssl/etcd-key.pem
insecureSkipVerify: true
selector:
matchLabels:
k8s-app: etcd
namespaceSelector:
matchNames:
- kube-system
上面这个文件我们匹配 Kube-system 这个命名空间下面具有 k8s-app=etcd 这个label标签的Service,job label用于检索job任务名称的标签。由于证书 serverName 和 etcd 中签发的证书可能不匹配,所以添加了 insecureSkipVerify=true 将不再对服务端的证书进行校验。接下来我们直接创建这个ServiceMonitor:
# 创建资源文件
kubectl apply -f prometheus-serviceMonitorEtcd.yaml
# 查看servicemonitors资源
kubectl get servicemonitors -n monitoring |grep etcd

ServiceMonitor资源创建完成以后、我们等30秒然后刷新Prometheus Targets数据。此时我们发现新增了一条 monitoring/etcd-k8s/0 (0/0 up) ,但是没有任何数据。那是因为我们虽然创建了ServiceMonitor,但是还没有关联对应的Service对象,所以需要创建一个service对象。
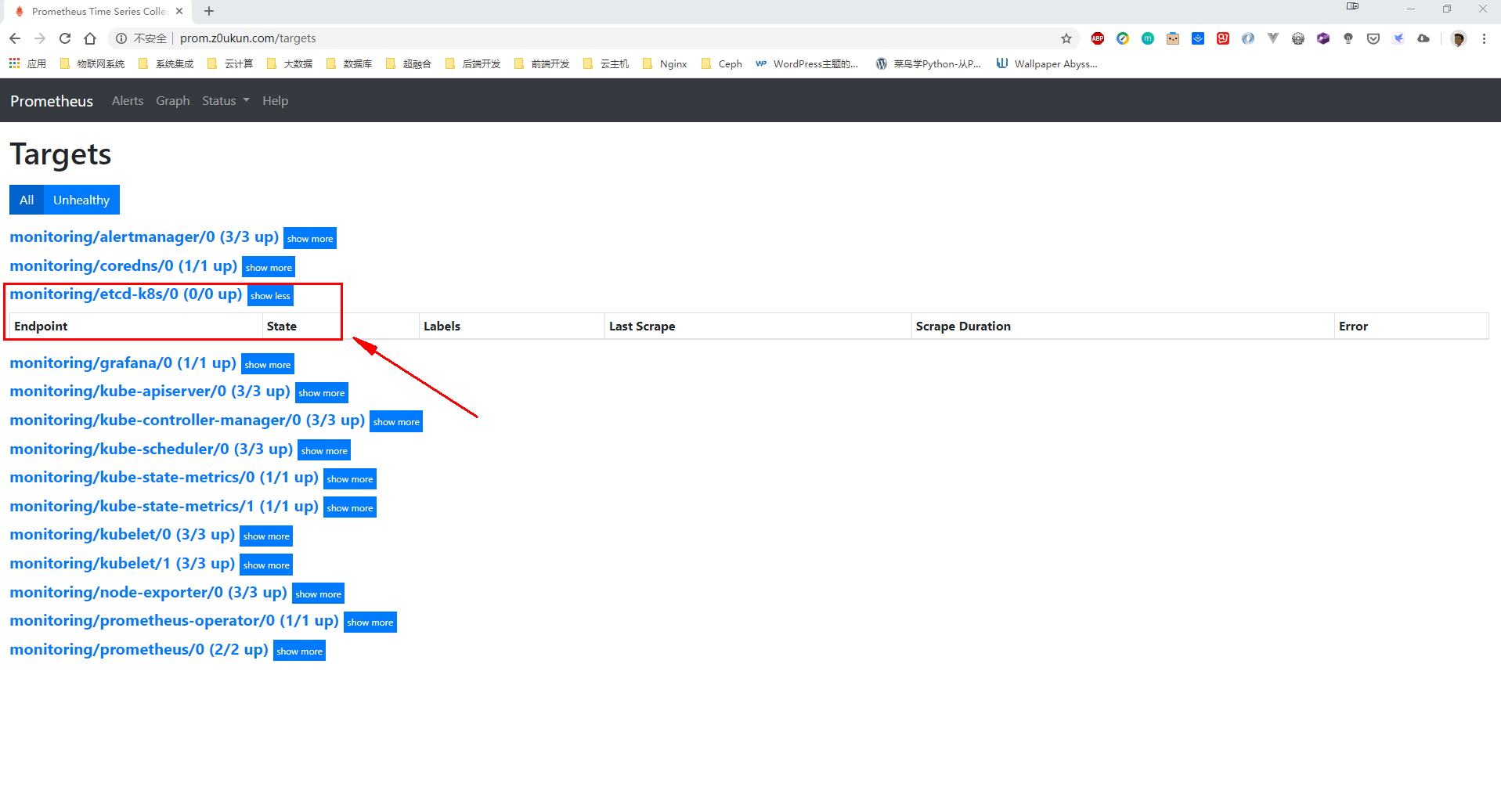
我们需要定义一个 Service 对象和一个 Endpoints,对应资源文件如下。
prometheus-EtcdService.yaml:
apiVersion: v1
kind: Service
metadata:
name: etcd-k8s
namespace: kube-system
labels:
k8s-app: etcd
spec:
type: ClusterIP
clusterIP: None
ports:
- name: port
port: 2379
protocol: TCP
prometheus-EtcdServiceEnpoints.yaml
apiVersion: v1
kind: Endpoints
metadata:
name: etcd-k8s
namespace: kube-system
labels:
k8s-app: etcd
subsets:
- addresses:
- ip: 172.16.200.11 #etcd节点名称
#nodeName: k8s-01 #kubelet名称 (kubectl get node)显示的名称
- ip: 172.16.200.12
#nodeName: k8s-02
- ip: 172.16.200.13
#nodeName: k8s-03
ports:
- name: port
port: 2379
protocol: TCP
然后我们直接创建上面的 Service 对象和 Endpoints 对象:
kubectl apply -f prometheus-EtcdService.yaml
kubectl apply -f prometheus-EtcdServiceEnpoints.yaml
# 查看ETCD状态
kubectl describe svc -n kube-system etcd-k8s

创建完成后,稍等一会我们可以去Prometheus 里面查看targets,便会出现etcd监控信息:
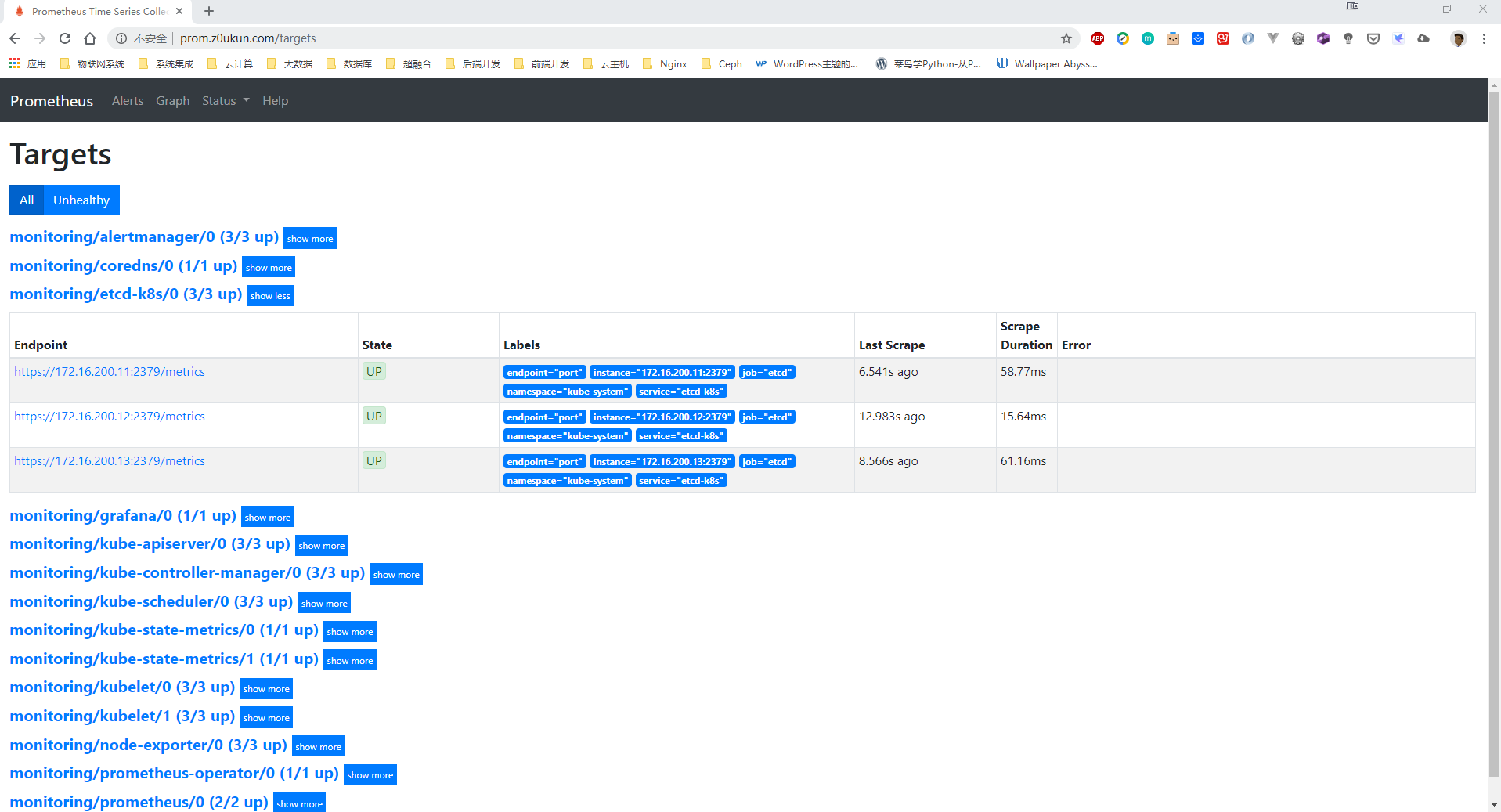
注:如果提示ip:2379 connection refused,首先检查本地Telnet 是否正常,在检查etcd配置文件是否是监听0.0.0.0:2379。
数据采集完成后,接下来可以在grafana中导入dashboard。这里我们可以导入 :https://grafana.com/grafana/dashboards/3070;还可以导入中文版ETCD集群插件:https://grafana.com/grafana/dashboards/9733;导入过程这里就不再详细描述了、不会的小伙伴请自行百度:
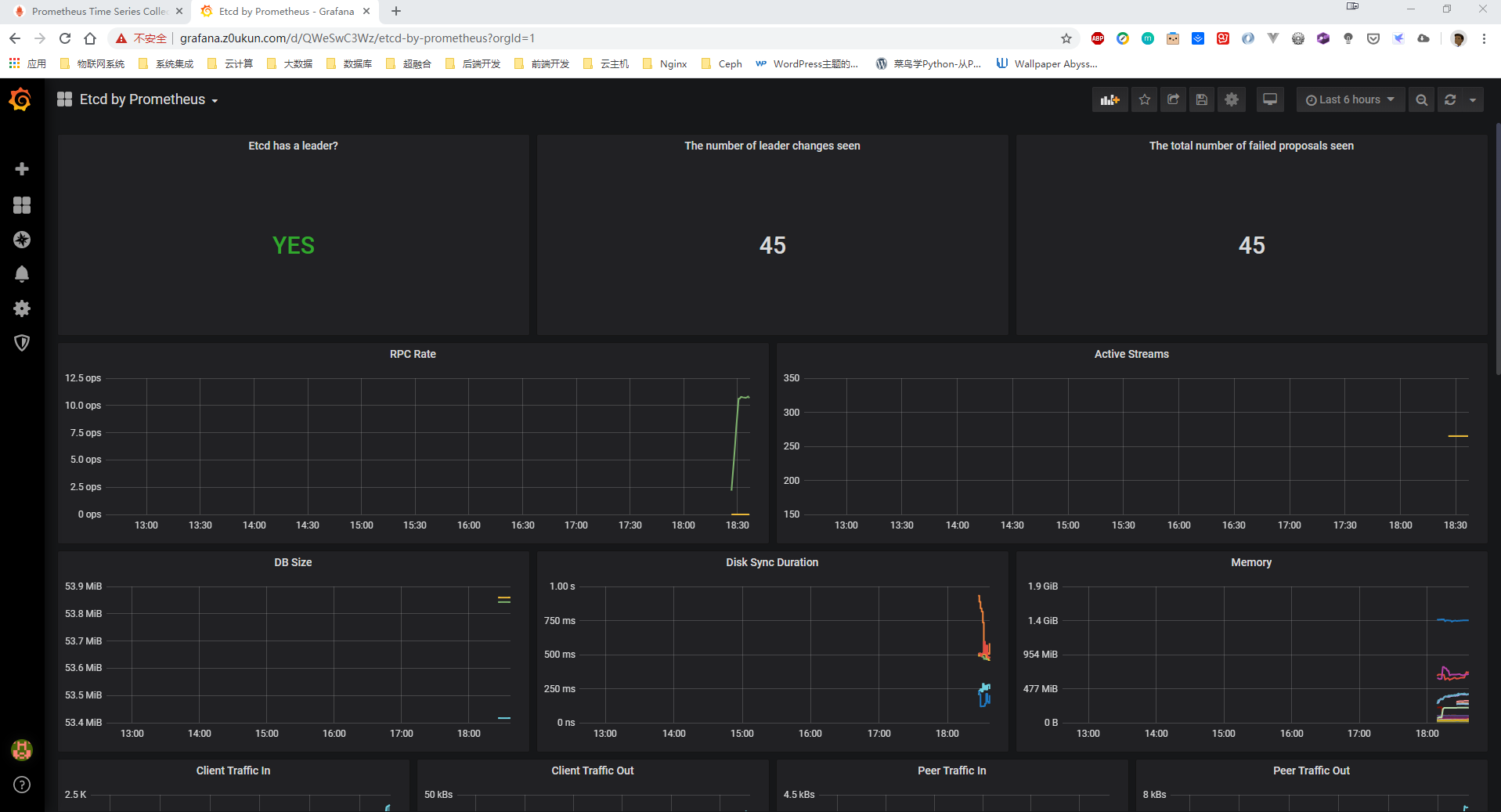
4、Kube-Prometheus数据持久化
前面我们需改完Prometheus的相关配置后,重启了 Prometheus 的 Pod,如果我们仔细观察的话会发现我们之前采集的数据已经没有了,这是因为我们通过 Prometheus 这个 CRD 创建的 Prometheus 并没有做数据的持久化,我们可以直接查看生成的 Prometheus Pod 的挂载情况就清楚了:
kubectl get pod prometheus-k8s-0 -n monitoring -o yaml

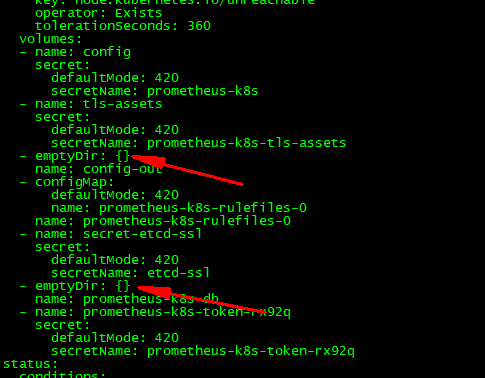
从上图我们可以看到 Prometheus 的数据目录 /prometheus 实际上是通过 emptyDir 进行挂载的,我们知道 emptyDir 挂载的数据的生命周期和 Pod 生命周期一致的,所以如果 Pod 挂掉了,数据也就丢失了,这也就是为什么我们重建 Pod 后之前的数据就没有了的原因,对应线上的监控数据肯定需要做数据的持久化的,同样的 prometheus 这个 CRD 资源也为我们提供了数据持久化的配置方法,由于我们的 Prometheus 最终是通过 Statefulset 控制器进行部署的,所以我们这里需要通过 storageclass 来做数据持久化,首先创建一个 StorageClass 对象(prometheus-storageclass.yaml):
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: prometheus-data-db
provisioner: fuseim.pri/ifs
这里我们声明一个 StorageClass 对象,其中 provisioner=fuseim.pri/ifs,则是因为我们集群中使用的是 nfs 作为存储后端,而前面我们创建的 nfs-client-provisioner 中指定的 PROVISIONER_NAME 就为 fuseim.pri/ifs,这个名字不能随便更改。然后我们直接创建这个资源:
kubectl apply -f prometheus-storageclass.yaml
kubectl get storageclass

然后在 prometheus 的 CRD 资源对象中添加如下配置:
storage:
volumeClaimTemplate:
spec:
storageClassName: prometheus-data-db
resources:
requests:
storage: 100Gi

注意这里的 storageClassName 名字为上面我们创建的 StorageClass 对象名称,然后更新 prometheus 这个 CRD 资源。更新完成后会自动生成两个 PVC 和 PV 资源对象:
# 更新资源文件
kubectl apply -f prometheus-prometheus.yaml
# 查看PVC
kubectl get pvc -n monitoring
# 查看PV
kubectl get pv

现在我们再去看 Prometheus Pod 的数据目录就可以看到是关联到一个 PVC 对象上了。现在即使我们的 Pod 挂掉了,数据也不会丢失了。
5、Kube-Prometheus数据持久时间
前面说了prometheus operator持久化的问题,但是还有一个问题很多人都忽略了,那就是prometheus operator数据保留天数,根据官方文档的说明,默认prometheus operator数据存储的时间为1d,这个时候无论你prometheus operator如何进行持久化,都没有作用,因为数据只保留了1天,那么你是无法看到更多天数的数据。
官方文档可以配置的说明:https://github.com/coreos/prometheus-operator/blob/0e6ed120261f101e6f0dc9581de025f136508ada/Documentation/prometheus.md
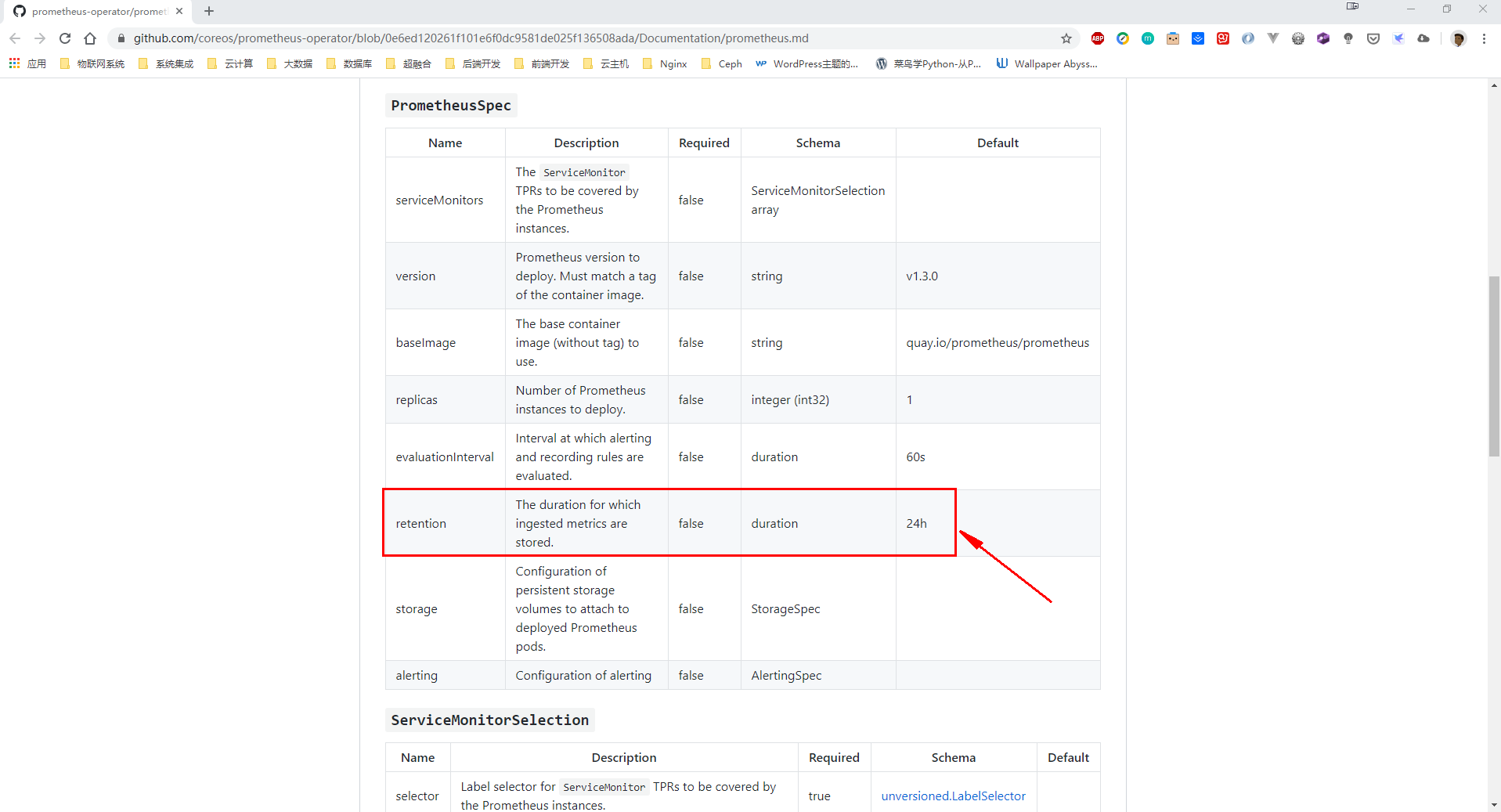
实际上我们修改 Kube-Prometheus 时间是通过 retention 参数进行修改,上面也提示了在prometheus.spec下填写。这里我们直接修改 prometheus-prometheus.yaml 文件,并添加下面的参数:
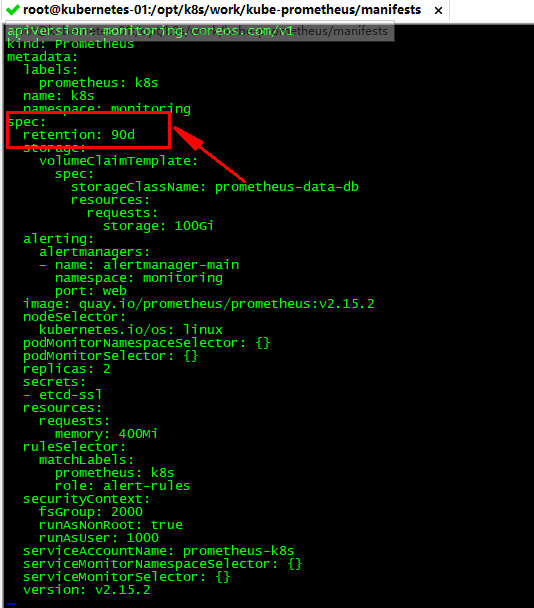
注:如果已经安装了可以直接修改 prometheus-prometheus.yaml 然后通过kubectl apply -f 刷新即可,修改完成以后记得检查Pod运行状态是否正常。
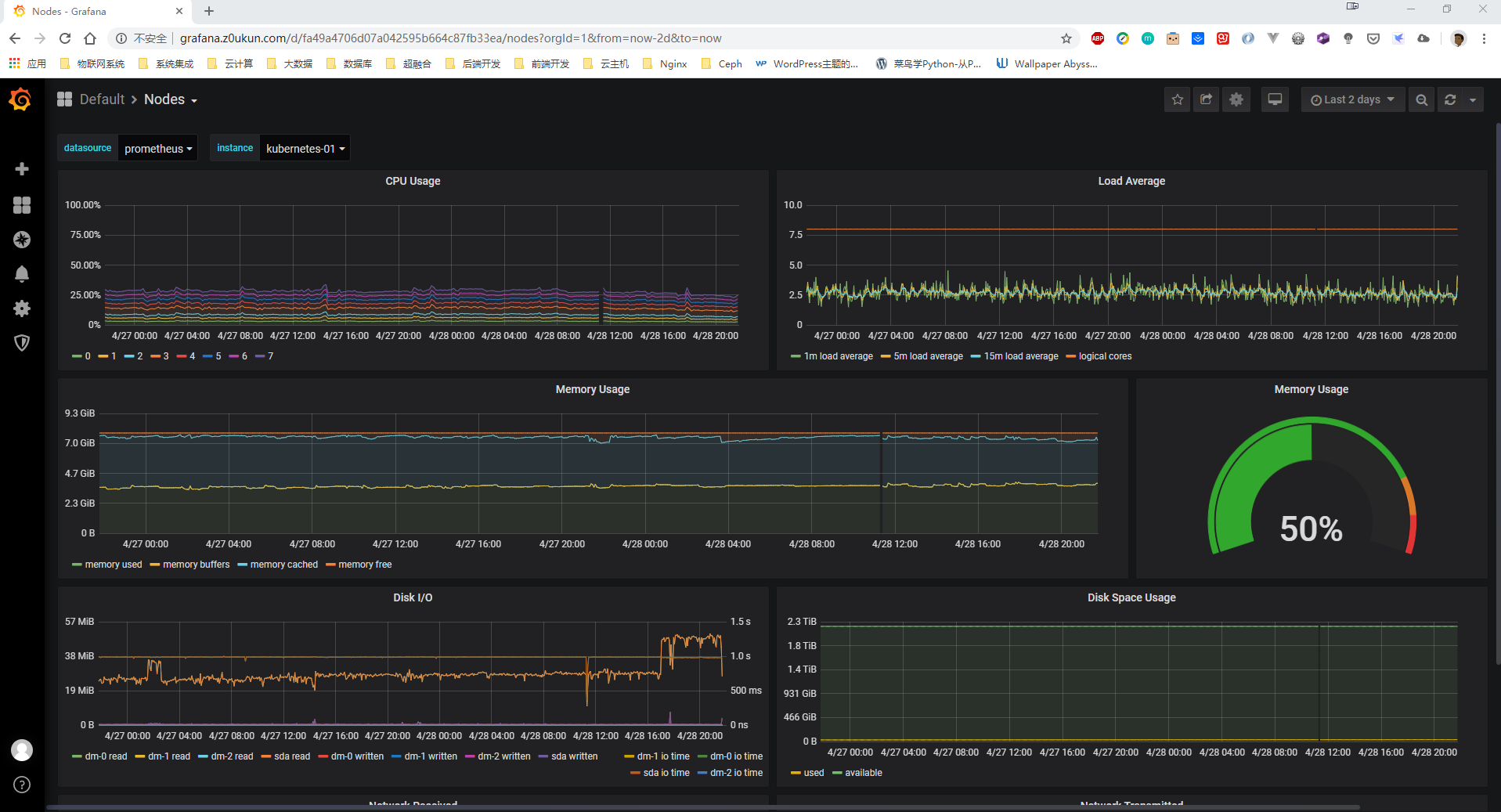
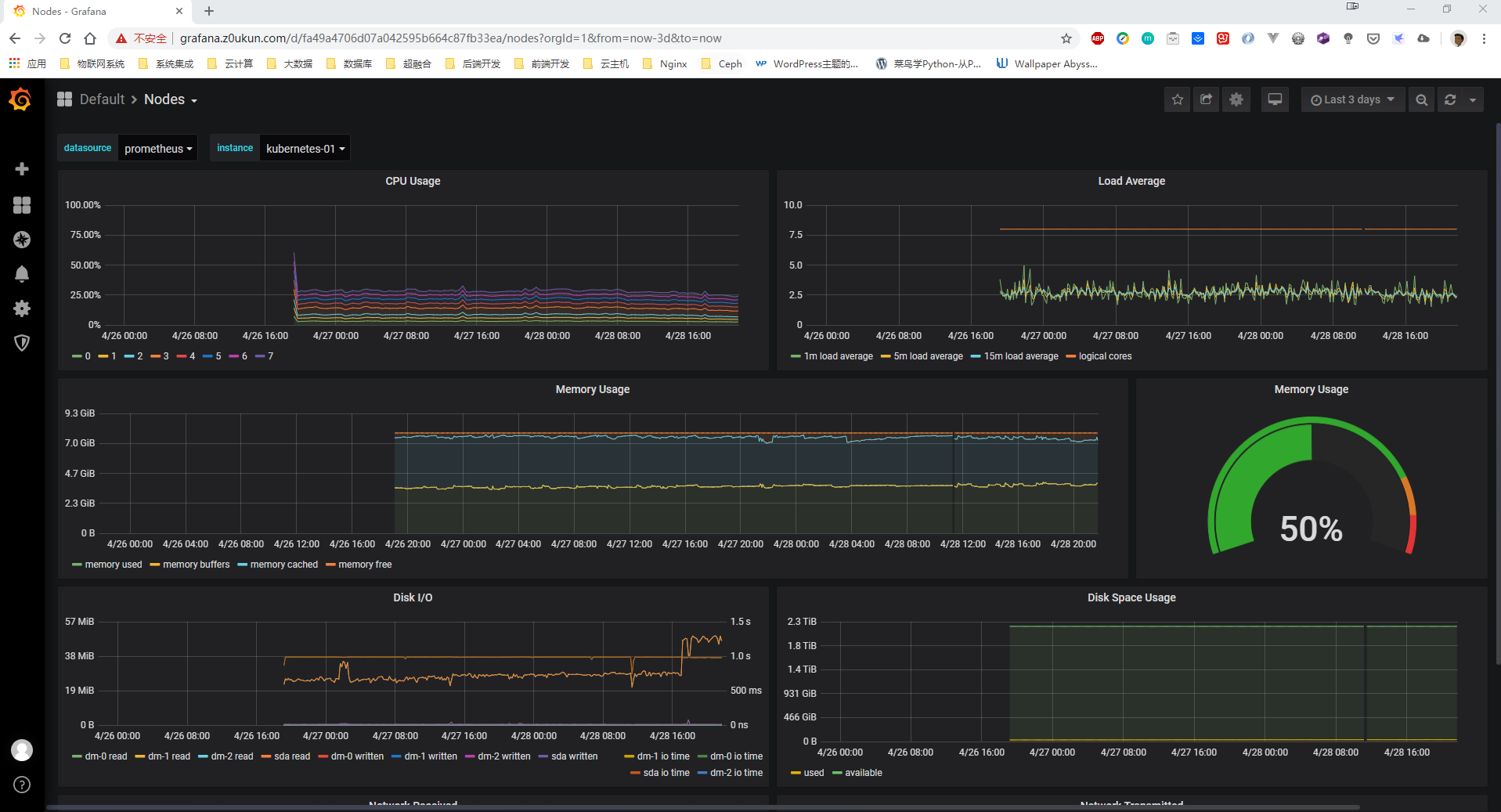
接下来可以访问grafana或者prometheus ui进行检查 (我这里修改完毕后等待2天,检查数据是否正常)。
修改前

修改后
6、Grafana数据持久化
前面我们介绍了关于prometheus的数据持久化、但是没有介绍如何针对Grafana做数据持久化;如果Grafana不做数据持久化、那么服务重启以后,Grafana里面配置的Dashboard、账号密码等信息将会丢失;所以Grafana做数据持久化也是很有必要的。
原始的数据是以 emptyDir 形式存放在pod里面,生命周期与pod相同;出现问题时,容器重启,在Grafana里面设置的数据就全部消失了。
volumeMounts:
- mountPath: /var/lib/grafana
name: grafana-storage
readOnly: false
...
volumes:
- emptyDir: {}
name: grafana-storage
从上图我们可以看出Grafana将dashboard、插件这些数据保存在/var/lib/grafana这个目录下面。做持久化的话,就需要对这个目录进行volume挂载声明。
我们把emptyDir修改为pvc方式:
volumes:
- name: grafana-storage
persistentVolumeClaim:
claimName: grafana
如果要使用一个 pvc 对象来持久化数据,我们就需要添加一个可用的 pv 供 pvc 绑定使用,grafana-volume.yaml内容如下:
apiVersion: v1
kind: PersistentVolume
metadata:
name: grafana
spec:
capacity:
storage: 10Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Recycle
nfs:
server: 172.16.200.10
path: /mnt/lv/k8s
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: grafana
namespace: monitoring
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
然后我们直接创建上面的PV和PVC、更新 grafana-deployment.yaml 文件即可:
# kubectl apply -f grafana-volume.yaml
# kubectl apply -f grafana-deployment.yaml
创建完成以后我们查看Pod状态,我们发现Pod状态一直是 CrashLoopBackOff 没有正常启动,我们再看一下这个 Pod 的日志,错误信息如下:
mkdir: cannot create directory '/var/lib/grafana/plugins': Permission denied
这个错误是 Grafana 5.1版本以后才会出现的。错误的原因很明显,就是 /var/lib/grafana 目录的权限不够。在 “ 中有这样一个属性:
securityContext:
runAsNonRoot: true
runAsUser: 65534
我们查看一下65534是哪个用户:
cat /etc/passwd | grep 65534
所以,我们只需要把 /mnt/lv/k8s 目录的用户改为 nfsnobody 就可以了。当然把属性改为 777 也没问题:
chown nfsnobody /mnt/lv/k8s
把刚才出错的那个 Pod 删除,新的 Grafana Pod 就成功启动了。然后就可以添加 Dashboard 了,现在Pod 重建也不会丢失数据了。
7、Kube-Prometheus服务发现
前面我们在 Kube-Prometheus 下面自定义一个监控项,以及自定义报警规则的使用。那么我们还能够直接使用前面课程中的自动发现功能吗?如果在我们的 Kubernetes 集群中有了很多的 Service/Pod,那么我们都需要一个一个的去建立一个对应的 ServiceMonitor 对象来进行监控吗?这样岂不是又变得麻烦起来了?
为解决上面的问题,Kube-Prometheus 为我们提供了一个额外的抓取配置的来解决这个问题,我们可以通过添加额外的配置来进行服务发现进行自动监控。和前面自定义的方式一样,我们可以在 Kube-Prometheus 当中去自动发现并监控具有prometheus.io/scrape=true 这个 annotations 的 Service,之前我们定义的 Prometheus 的配置如下:
- job_name: 'kubernetes-endpoints'
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
action: replace
target_label: __scheme__
regex: (https?)
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]
action: replace
target_label: __address__
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: kubernetes_name
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: kubernetes_pod_name
要想自动发现集群中的 Service,就需要我们在 Service 的 annotation 区域添加 prometheus.io/scrape=true 的声明,将上面文件直接保存为 prometheus-additional.yaml,然后通过这个文件创建一个对应的 Secret 对象:
kubectl create secret generic additional-configs --from-file=prometheus-additional.yaml -n monitoring
然后我们需要在声明 prometheus 的资源对象文件中通过 additionalScrapeConfigs 属性添加上这个额外的配置:(prometheus-prometheus.yaml)
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:
labels:
prometheus: k8s
name: k8s
namespace: monitoring
spec:
retention: 365d
storage:
volumeClaimTemplate:
spec:
storageClassName: prometheus-data-db
resources:
requests:
storage: 100Gi
alerting:
alertmanagers:
- name: alertmanager-main
namespace: monitoring
port: web
baseImage: quay.io/prometheus/prometheus
nodeSelector:
kubernetes.io/os: linux
podMonitorNamespaceSelector: {}
podMonitorSelector: {}
replicas: 2
secrets:
- etcd-ssl
resources:
requests:
memory: 400Mi
ruleSelector:
matchLabels:
prometheus: k8s
role: alert-rules
securityContext:
fsGroup: 2000
runAsNonRoot: true
runAsUser: 1000
serviceAccountName: prometheus-k8s
serviceMonitorNamespaceSelector: {}
serviceMonitorSelector: {}
version: v2.11.0
# 添加额外配置内容
additionalScrapeConfigs:
name: additional-configs
key: prometheus-additional.yam
添加完成后,直接更新 prometheus 这个 CRD 资源对象即可:
kubectl apply -f prometheus-prometheus.yaml
隔一小会儿,可以前往 Prometheus 的 Dashboard 中查看配置已经生效了:
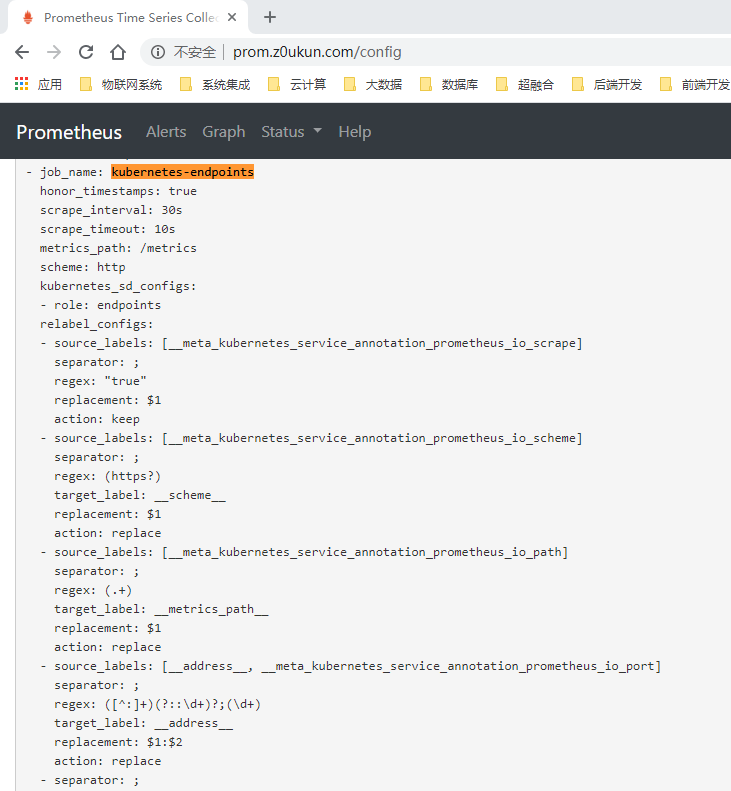
但是我们切换到 targets 页面下面却并没有发现对应的监控任务,查看 Prometheus 的 Pod 日志:
kubectl logs -f prometheus-k8s-0 prometheus -n monitoring | grep cluster
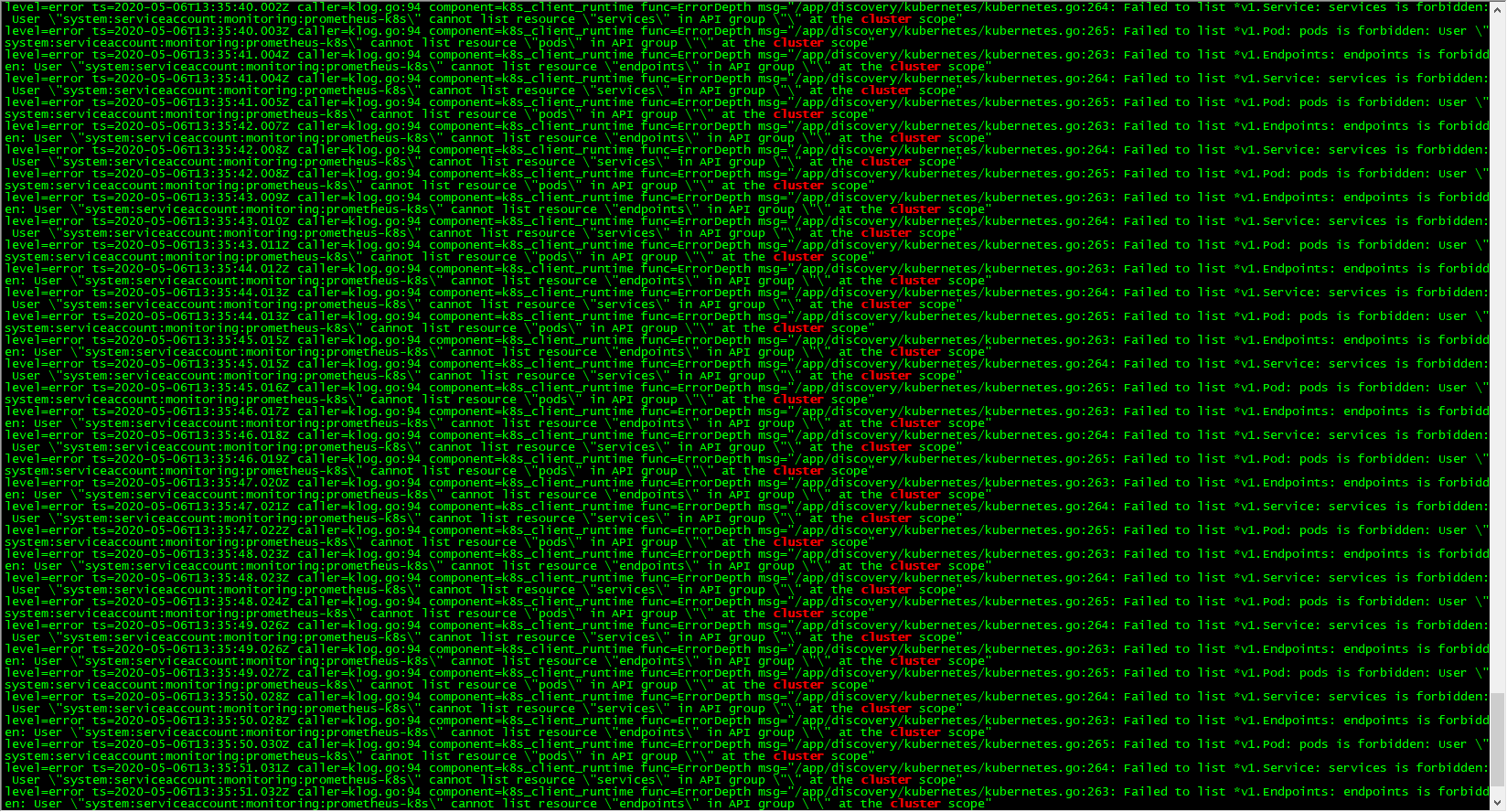
可以看到有很多错误日志出现,都是 xxx is forbidden,这说明是 RBAC 权限的问题,通过 prometheus 资源对象的配置可以知道 Prometheus 绑定了一个名为 prometheus-k8s 的 ServiceAccount 对象,而这个对象绑定的是一个名为 prometheus-k8s 的 ClusterRole:(prometheus-clusterRole.yaml)
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: prometheus-k8s
rules:
- apiGroups:
- ""
resources:
- nodes/metrics
verbs:
- get
- nonResourceURLs:
- /metrics
verbs:
- get
上面的权限规则中我们可以看到明显没有对 Service 或者 Pod 的 list 权限,所以报错了,要解决这个问题,我们只需要添加上需要的权限即可:
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: prometheus-k8s
rules:
- apiGroups:
- ""
resources:
- nodes
- services
- endpoints
- pods
- nodes/proxy
verbs:
- get
- list
- watch
- apiGroups:
- ""
resources:
- configmaps
- nodes/metrics
verbs:
- get
- nonResourceURLs:
- /metrics
verbs:
- get
更新上面的 ClusterRole 这个资源对象,然后重建 Prometheus 的所有 Pod,正常就可以看到 targets 页面下面有 kubernetes-endpoints 这个监控任务了:
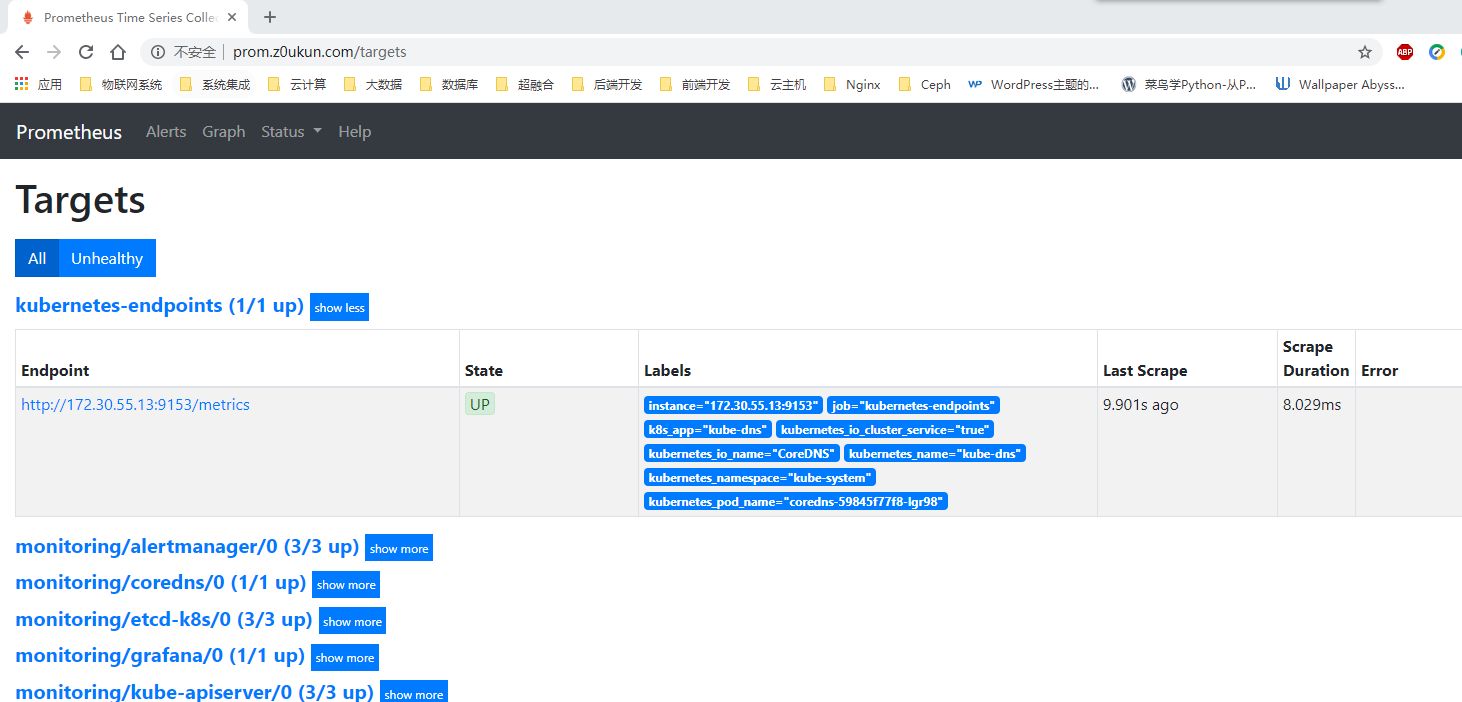
从上图我们可以看到、上面抓取的目标是因为 Service 中有 prometheus.io/scrape=true 这个 annotation。