1、集群环境
本教程参考:庖丁解牛Ceph分布式存储 ,感兴趣的同学也可以去看看51cto的原文。
Ceph官方网站:https://ceph.io/
Ceph中文官方文档:http://docs.ceph.org.cn/
今天我们讲解如何快速部署Ceph分布式高可用集群。目前Ceph官方提供三种部署Ceph集群的方法,分别是ceph-deploy,cephadm和手动安装:
- ceph-deploy,一个集群自动化部署工具,使用较久,成熟稳定,被很多自动化工具所集成,可用于生产部署;
- cephadm,从Octopus开始提供的新集群部署工具,支持通过图形界面或者命令行界面添加节点,目前不建议用于生产环境,有兴趣可以尝试;
- manual,手动部署,一步步部署Ceph集群,支持较多定制化和了解部署细节,安装难度较大,但可以清晰掌握安装部署的细节。
当然、安装方式有多种、俗话说条条大路通罗马、自己能理解方法就是好方法。这里我们采用成熟、简单的ceph-deploy实现Ceph集群的部署。在开始之前,我们先了解一下ceph-deploy的基础架构:

- admin-node:需要一个安装管理节点,安装节点负责集群整体部署,这里我们用CephNode01为admin-node和Ceph-Mon节点;
- mon:monitor节点,即是Ceph的监视管理节点,承担Ceph集群重要的管理任务,一般需要3或5个节点,此处部署简单的一个Monitor节点;
- osd:OSD即Object Storage Daemon,实际负责数据存储的节点,3个节点上分别有2块100G的磁盘充当OSD角色。
注:生产环境如果有多个节点也可以继续横向扩容;如果磁盘容量不够也可以根据使用需求进行纵向扩容。
这里我们安装3节点Ceph集群,集群信息如下:
硬件环境:虚拟机,4core+4G+100G系统盘+100G数据盘+100G数据盘
操作系统:CentOS Linux release 7.7.1908 (Core)
软件版本:nautilus 14.2.8
部署版本:ceph-deploy 2.0.1
Ceph网络:Ceph Cluster网络均采用192.167.17.0/24,Ceph Public网络采用192.167.17.0/24
注:原文这里复用了Public网络和Cluster网络、这里我们采用两个网络进行互通。
集群规划:
- CephNode-01:192.167.17.134/192.168.18.134
- CephNode-02:192.167.17.135/192.168.18.135
- CephNode-03:192.167.17.136/192.168.18.136
2、系统初始化
注:如果没有特殊说明,本小节所有操作需要在所有节点上执行本文档的初始化操作。
配置主机名
# 可以将下面的节点名称替换为自己的主机名称
hostnamectl set-hostname CephNode-01
hostnamectl set-hostname CephNode-02
hostnamectl set-hostname CephNode-03
如果 DNS 不支持主机名称解析,还需要在每台机器的 /etc/hosts 文件中添加主机名和 IP 的对应关系:
cat >> /etc/hosts <<EOF
# Ceph Cluster Network
192.167.17.134 CephNode-01
192.167.17.135 CephNode-02
192.167.17.136 CephNode-03
# Ceph Public Network
192.168.18.134 CephNode-01
192.168.18.135 CephNode-02
192.168.18.136 CephNode-03
EOF

然后退出,重新登录 root 账号,可以看到主机名生效。
添加节点SSH互信
ssh-keygen -t rsa
ssh-copy-id root@CephNode-01
ssh-copy-id root@CephNode-02
ssh-copy-id root@CephNode-03

关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
iptables -F && iptables -X && iptables -F -t nat && iptables -X -t nat
iptables -P FORWARD ACCEPT
注:关闭防火墙,清理防火墙规则,设置默认转发策略。
关闭swap分区
swapoff -a
sed -i '/ swap / s/^\(.*\)$/#\1/g' /etc/fstab
注:关闭 swap 分区。
关闭SELinux
setenforce 0
sed -i 's/^SELINUX=.*/SELINUX=disabled/' /etc/selinux/config
注:关闭 SELinux。
配置EPEL源
配置yum源,由于网络环境因素,因此将yum源统一配置到国内阿里云,加快rpm的安装配置,需要配置CentOS的基础源、EPEL源和Ceph源:
# 删除默认yum源并配置阿里yum源
rm -f /etc/yum.repos.d/*.repo
wget http://mirrors.aliyun.com/repo/Centos-7.repo -P /etc/yum.repos.d/
# 安装EPEL源
wget http://mirrors.aliyun.com/repo/epel-7.repo -P /etc/yum.repos.d/
配置Ceph源
cat > /etc/yum.repos.d/ceph.repo <<EOF
[noarch]
name=Ceph noarch
baseurl=https://mirrors.aliyun.com/ceph/rpm-nautilus/el7/noarch/
enabled=1
gpgcheck=0
[x86_64]
name=Ceph x86_64
baseurl=https://mirrors.aliyun.com/ceph/rpm-nautilus/el7/x86_64/
enabled=1
gpgcheck=0
EOF

安装依赖包
安装Ceph-deploy部署工具,默认EPEL源提供的ceph-deploy版本是1.5,务必确保安装版本为2.0.1或之上版本,否则安装过程中会有很多问题。
# 更新yum源
yum update -y
# 安装工具包、python-setuptools一定要安装、不然会报错的
yum install -y chrony conntrack ipset jq iptables curl sysstat libseccomp wget socat git python-setuptools
# 安装ceph-deploy部署工具
yum install ceph-deploy -y
#校验版本
ceph-deploy --version


配置系统时间
timedatectl set-timezone Asia/Shanghai
配置时钟同步
timedatectl status
注:System clock synchronized: yes,表示时钟已同步; NTP service: active,表示开启了时钟同步服务。
写入硬件时钟
# 将当前的 UTC 时间写入硬件时钟
timedatectl set-local-rtc 0
# 重启依赖于系统时间的服务
systemctl restart rsyslog
systemctl restart crond
关闭无关服务
systemctl stop postfix && systemctl disable postfix
执行完上面所有的操作之后我们就可以重启所有主机了:
sync
reboot
3、部署Ceph集群
Ceph系统初始化完成以后、现在我们通过Ceph-deploy开始部署Ceph集群。Ceph-deploy部署过程中会生成一些集群初始化配置文件和key,后续扩容的时候也需要使用到,因此,建议在admin-node上创建一个单独的目录,后续操作都进入到该目录中进行操作,以创建的ceph-admin为例。这里我在/root/下面创建一个ceph-admin目录:
mkdir -p ceph-admin
# 后续所有的操作均需要在ceph-admin目录下面完成
cd ceph-admin
现在我们开始安装Ceph所需的安装包,安装过程中可以使用ceph-deploy install提供的安装方式。这个命令会自动安装EPEL源,重新设定Ceph源;这里我们已经设置到国内源了,因此采用手动安装Ceph安装包方式,为了保障后续的安装,我们在三个节点上将Ceph的安装包都部署上,我们在三个节点上分别执行下面的命令即可:
yum install ceph-mon ceph-radosgw ceph-mds ceph-mgr ceph-osd ceph-common -y

注:上面的命令会自动安装所有需要的依赖包。
现在我们执行下面的命令创建一个Ceph Cluster集群,这里我们需要制定cluster-network(集群内部通讯)和public-network(外部访问Ceph集群):
ceph-deploy new --cluster-network 192.167.17.0/24 --public-network 192.168.18.0/24 CephNode-01

注:大家可以根据自己的环境修改上面的网段。
通过上面的输出可以看到,new初始化集群过程中会生成ssh key密钥,ceph.conf配置文件,ceph.mon.keyring认证管理密钥,配置cluster network和pubic network,此时查看目录下的文件可以看到如下内容:

现在我们开始初始化monitor节点,我们直接执行下面的命令即可完成Ceph集群初始化,初始化完毕后会自动生成以下几个文件,这些文件用于后续和Ceph认证交互使用:
ceph-deploy mon create-initial

初始化完成之后我们将admin的认证密钥拷贝到其他节点上,便于ceph命令行可以通过keyring和ceph集群进行交互:
ceph-deploy admin cephnode-01 cephnode-02 cephnode-03

此时,Ceph集群已经建立起来,当前的Ceph集群包含一个monitor节点,通过 ceph -s 我们可以查看当前ceph集群的状态;但是此时并没有任何的OSD节点,因此无法往集群中写数据等操作,如下:

从上面的截图我们可以看到、目前集群中目前还没有OSD节点;因此没法存储数据,接下来开始往集群中添加OSD节点,在前面我们说过每个节点上都有2块100G的磁盘,分别是/dev/sdb和/dev/sdc;下面我们将其加入到集群中作为OSD节点:

执行下面的命令,将 /dev/sdb 磁盘加入到集群中:
ceph-deploy osd create cephnode-01 --data /dev/sdb

从上面的截图我们可以看到、我们已经将cephnode-01的 /dev/sdb 磁盘添加到ceph集群中;我们可以采用相同的方式把 cephnode-02的 /dev/sdb 磁盘和cephnode-03的 /dev/sdb 磁盘页加入到集群中来:
ceph-deploy osd create cephnode-02 --data /dev/sdb
ceph-deploy osd create cephnode-03 --data /dev/sdb


添加完成之后我们可以通过 ceph -s 命令查看集群OSD状态;我们可以看到当前集群中已经有3个对应的OSD节点:
当然、我们也可以通过ceph osd tree查看osd的列表情况,可以清晰看到osd在对应node节点,以及当前状态:

至此Ceph集群已经部署完毕,但是通过 ceph -s 我们可以看到当前的集群状态为 HEALTH_WARN(即告警状态),告警信息为“no active mgr”。那是因为我们并没有在当前集群没有安装manager节点,因此会有告警信息。现在我们需要将 mgr 部署到 cephnode-01 节点上:
ceph-deploy mgr create cephnode-01

ceph-mgr 节点安装完毕后,我们再次通过ceph -s可以查看到当前集群已经处于 health_ok 健康状态:

4、资源池Pool管理
上面我们已经完成了 Ceph 集群的部署,但是我们如何向Ceph中存储数据呢?首先我们需要在 Ceph 中定义一个 pool 资源池,前面我们讲过 pool 是Ceph中存储object对象抽象概念。我们可以将其理解为 Ceph 存储上划分的逻辑分区,pool 由多个 pg 组成;而 pg 通过 CRUSH 算法映射到不同的OSD上;同时pool可以设置副本size大小,默认副本数量为3。

注:Ceph客户端向 monitor 请求集群的状态,并向 pool 中写入数据,数据根据 PGs 的数量,通过CRUSH 算法将其映射到不同的 OSD 节点上,实现数据的存储;这里我们可以把 pool 理解为存储object数据的逻辑单元;当然、当前集群没有资源池,因此需要进行定义。
现在我们开始创建一个 pool 资源池,其名字为 z0ukun,PGs 数量设置为 64,设置 PGs 的同时还需要设置 PGP(通常PGs和PGP的值是相同的):
cd ceph-admin
ceph osd pool create z0ukun 64 64

pool 创建成功之后,我们可以通过 ceph osd lspools 查看当前集群的 pool 信息:
# 查看集群 pool 信息
ceph osd lspools

默认创建的资源池包含3个副本,我们可以通过 ceph osd pool get size 查看资源池副本的数量,
ceph osd pool get z0ukun size

我们可以看到副本数量为3。
除此之外,我们还可以通过下面的命令查看PGs和PGP数量:
# ceph osd pool get z0ukun pg_num
# ceph osd pool get z0ukun pgp_num

当然、如果有需要,我们也可以调整 pool 的相关参数,比如我们将 pool 副本数量调整为2:
# 调整 pool 副本数量为2
ceph osd pool set z0ukun size 2
# 查看 pool 副本数量
ceph osd pool get z0ukun size

可以看到,当前已经调整pool副本的数量至2副本,也可以调整其他参数,如pg_num,pgp_num。例如我们分别调整pg_num和pgp_num的数量为128:
# 调整pg_num和pgp_num
ceph osd pool set z0ukun pg_num 128
ceph osd pool set z0ukun pgp_num 128

# 查看pg_num和pgp_num
ceph osd pool get z0ukun pg_num
ceph osd pool get z0ukun pgp_num

注:这里需要特别说明一下、如果在生产环境中调整 pool 的参数可能会涉及到数据的迁移,因此调整时候需要重点评估再做调整。
5、Ceph集群扩容
5.1、Ceph Monitor 扩容
通过上述的步骤,我们已经完成了Ceph集群的部署。但是,此时Ceph集群的monitor是单点,一旦cephnode-01出现故障,整个集群将处于不可用的状态,因此需要部署monitor的高可用。由于monitor使用Paxos算法,因此需要确保集群有2n+1个节点才能保障集群能够正常参与仲裁选举,我们将cephnode-02和cephnode-03也当作是monitor节点加入到集群中来:
通过下面的命令扩容monitor节点,将cephnode-02和cephnode-03以mointor的角色加入到集群中:
# 集群mon扩容
ceph-deploy mon add cephnode-02
ceph-deploy mon add cephnode-03

我们使用相同的方法,将cephnode-03节点以monitor的形式加入到集群中。执行完毕后,我们可以通过 ceph quorum_status –format json-pretty 查看当前集群仲裁选举的情况:
ceph quorum_status --format json-pretty

当然、也可以通过ceph -s可以查看集群状态:

我们可以看到当前Ceph集群的mon节点数量为3、分别是 cephnode-01,cephnode-02和cephnode-03。我们还可以通过ceph mon dump查看集群中monitor的状态:
ceph mon dump

稍等一会、我们通过 ceph -s 命令再次查看Ceph集群状态。我们可以看到当前健康状态为告警状态,错误信息为:2 daemons have recently crashed;意思是有两个 crashed 守护进程崩溃了:

我们通过 ceph crash ls-new 命令可以看到下面的两个 crashed 进程:

我们可以通过ceph crash info [id] 查看进程详细信息:

我们发现 crashed 进程确实崩溃了,通过查看官方文档,我们发现这个告警可以通过 archiving 来消除,消除之后就不会再有此告警信息了;官方文档解决方案如下:
https://docs.ceph.com/docs/master/mgr/crash/?highlight=crash
[https://docs.ceph.com/docs/master/rados/operations/health-checks/?highlight=backfillfull%20ratio](https://docs.ceph.com/docs/master/rados/operations/health-checks/?highlight=backfillfull ratio)
这里我们通过 ceph crash archive-all 命令消除此故障,消除完成之后我们再次通过 ceph -s 命令查看集群状态,我们可以集群健康状态已经OK了:

Ceph monitor扩容后,我们还需要修改部署节点的 ceph.conf 文件,然后将配置分发到集群中的所有节点,避免配置不一致:


将配置文件拷贝到集群中的三个节点cephnode-01,cephnode-02和cephnode-03:

至此,monitor扩容完毕,生产中一般部署3个或者5个节点的Monitor,确保集群高可用状态。
5.2、Ceph OSD 扩容
随着集群资源的不断增长,Ceph集群的空间可能会存在不够用的情况,因此需要对集群进行扩容,扩容通常包含两种:横向扩容和纵向扩容。横向扩容即增加台机器,纵向扩容即在单个节点上添加更多的OSD存储,以满足数据增长的需求,添加OSD的时候由于集群的状态(cluster map)已发生了改变,因此会涉及到数据的重分布(rebalancing),即 pool 的PGs数量是固定的,需要将PGs数平均的分摊到多个OSD节点上,如下图,我们将2个OSD扩容至3个OSD:

扩容后,Ceph集群的OSD map发生改变,需要将PGs移动至其他的节点上。前面我们为每个节点添加了两块磁盘分别是 /dev/sdb 和 /dev/sdc ,上面我们已经添加过 /dev/sdb 了,现在我们再来添加 cephnode-01节点和 cephnode-02 节点的 /dev/sdc 磁盘:
注:当前集群没有数据,我们将cephnode-03 节点的 /dev/sdc 磁盘,用于后面演示数据均衡的过程。
ceph-deploy osd create cephnode-01 --data /dev/sdc

节点扩容时首先需要进入到ceph-admin的目录下,然后执行 ceph-deploy osd create cephnode-01 –data /dev/sdc 命令将节点添加到集群中。添加OSD中会涉及到PGs的迁移,由于此时集群并没有数据,因此health的状态很快就变成OK,如果在生产中添加节点则会涉及到大量的数据的迁移。然后使用相同的方法,将另外一个cephnode-02 节点的 /dev/sdc 磁盘添加到集群中:
ceph-deploy osd create cephnode-02 --data /dev/sdc
添加完成之后,我们再次查看集群状态,此时我们可以看到Ceph集群已经包含了5个OSD节点:

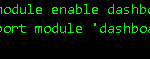
好了、到这里OSD节点扩容完成了、后面我们继续讲解如何通过Ceph原生dashboard实现Ceph管理可视化、并向大家介绍Ceph块存储、对象存储和文件存储的具体使用方法。