1、文件存储使用场景
传统存储中提供了NAS这种文件共享存储,通过网络协议如NFS,cifs 存储共享给多个客户端同时使用;NAS的好处是可以多个客户端共享,并且传输简单,只要有网络即可实现;当前在公有云环境下均提供有NAS对应的存储方案,例如:
- 1、AWS EFS(Elastic File System)弹性文件存储;
- 2、腾讯CFS(Cloud File System)云文件存储;
- 3、阿里NAS(Network Attached Storage)网络附加存储。
对于文件存储而言,客户端通过网络将远端的存储以 NFS 协议或者 cifs 协议挂载到本地。对于云上而言,其空间可以做到无限扩展,并且保障存储的性能。对于企业中的 NAS 设备而言,其存储空间是有限的,难以做到横向扩展,因此需要分布式式的存储来实现类似的功能。而 CephFS 就是 Ceph 上提供文件存储的接口。提到文件存储,除此 CephFS 之外,不得不提另外一个提供分布式文件存储的系统—GlusterFS,自从红帽收购 Ceph 之后,GlusterFS 使用的重心已转向Ceph。我们先来看一下 CephFS 的架构:
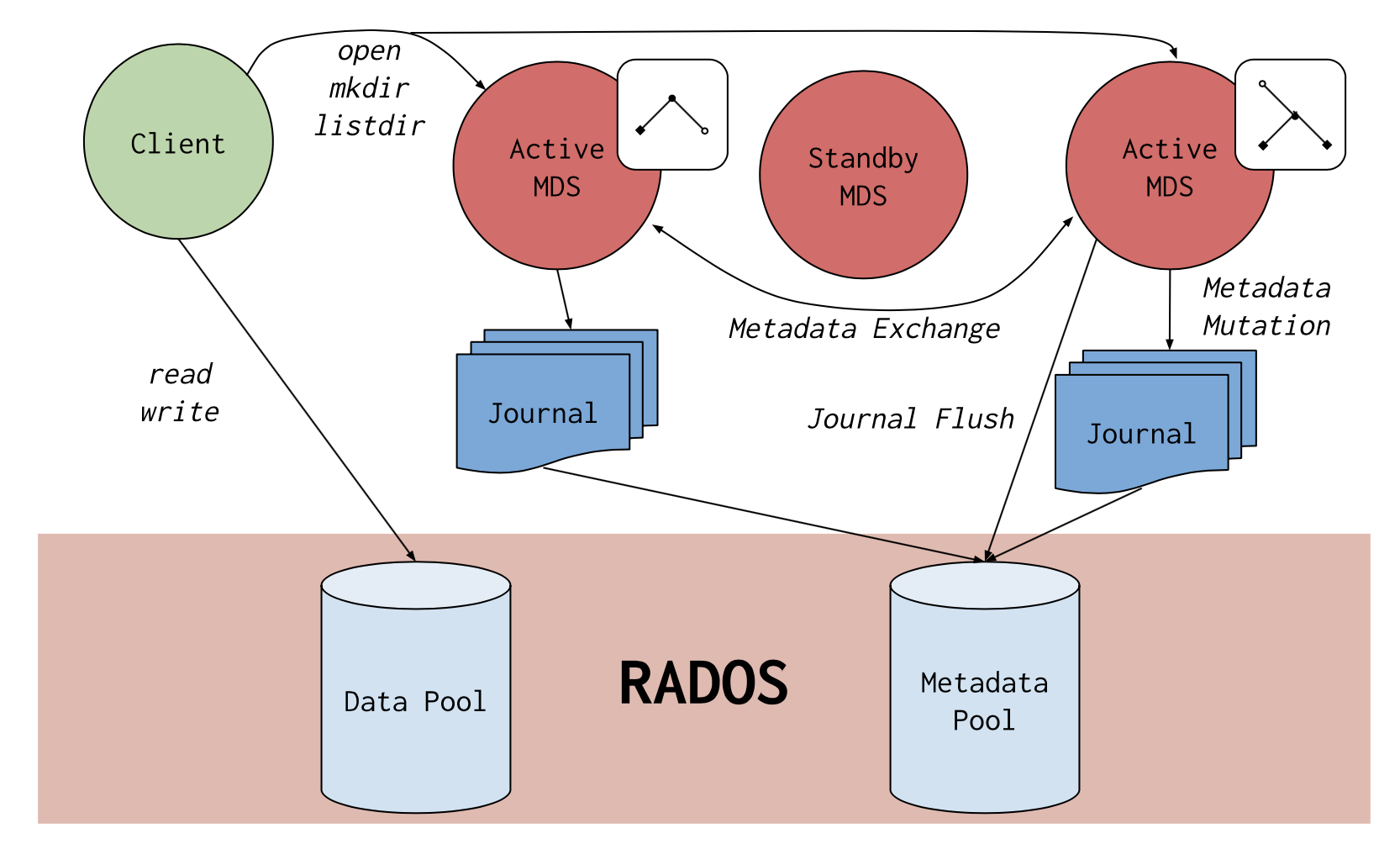
CephFS需要有个一个MDS(Meta Data Servers)元数据服务,其构建在RADOS之上,对客户端提供数据存储的服务;MDS由多个节点组成,节点之间使用 Active/Standby 模式,即主备模式对外提供服务,主节点的日志元数据信息记录在pool资源池上:由一个单独的资源池pool存放,MDS之间会定期交换metadata元数据信息;当主MDS异常时,备用的MDS会接管其功能,元数据信息将直接从journal资源池中获取,从而保障数据的一致性。
另外,对于数据的读写操作,客户端从metadata获取元数据之后,客户端对数据的读写操作直接到数据存储的资源池,从而将元数据和和数据存储资源池分开,构建MDS集群时需要创建两个pool,其中一个存放metadata元数据,另外一个存放实际data数据。
2、MDS集群安装部署
要使用CephFS,我们首先需要在集群中部署MDS节点,MDS节点是负责CephFS原数据存储的,我们通过ceph-deploy部署MDS,很容易实现目标要求。这里我们将 cephnode-01 节点部署为MDS节点(切记,部署前需要进入到部署目录)。
执行 ceph-deploy mds create cephnode-01 命令部署MDS服务:
# 部署MDS服务
cd ceph-admin
ceph-deploy mds create cephnode-01

为了MDS集群的高可用性,我们采用相同的方法再次将 cephnode-02 和 cephnode-03 作为MDS节点,加入到集群中,我们直接执行如下的命令即可:
# 部署MDS服务
ceph-deploy mds create cephnode-02
ceph-deploy mds create cephnode-03


部署完成以后我们使用 ceph -s 查看集群当前的状态,我们可以发现当前mds有三个节点,并且当前均属于standby状态:
# 查看集群状态
ceph -s

从上图我们可以看到整个Ceph集群的状态,但是为什么三个MDS节点都是 standby 状态呢?这是因为此时集群并未创建有mds文件系统,因此mds服务状态均为 standby,接下来我们来创建mds文件系统。创建mds文件系统,先创建两个资源池,cephfs_data 用于存储实际的数据,cephfs_metadata 用户存储元数据,元数据信息建议使用SSD加快访问效率:
# 测试
ceph osd pool create cephfs_data 64 64
ceph osd pool create cephfs_metadata 64 64

元数据创建完成之后,我们就可以来创建文件系统了:
# 创建文件系统
ceph fs new z0ukun-cephfs cephfs_metadata cephfs_data
# 查看文件系统状态
ceph fs ls

文件系统创建完成之后,我们通过 ceph fs ls 命令可以看到当前集群状态。我们可以看到上面创建的名为 z0ukun-cephfs 的 CephFS 文件系统;其使用 cephfs_metada 作为元数据,cephfs_data 作为数据存储。我们再次此时查看 mds 的服务状态,可以看到 cephnode-01 被选举为 active 主,另外两个承担standby的角色:
# 查看集群状态
ceph -s


至此,MDS集群部署完毕。
3、CephFSB客户端使用
CephFS提供了两种客户端和 CephFS 文件存储交互:内核的 cephfs 和用户态级别的 ceph-fuse,内核级别的 cephfs 性能上会优于 ceph-fuse,因此推荐使用 cephfs。使用 cephf 时需要认证信息,为了简便,我们使用默认提供的admin用于实现和CephFS的交互。
使用 CephFS 挂载文件系统:
# 文件系统挂载
mount.ceph :/ /media -o name=admin
# 查看文件系统挂载状态
df /media/ -h

从上图我们可以看到 CephFS 的整个存储空间都挂载到了目录中,在系统中以一个目录的方式来使用,此时我们可以往目录中存放数据。挂载完毕后,我们也可以看到系统中多了一个 ceph 的模块,我们可以通过 lsmod 命令来查看:
# 查看ceph模块
lsmod | grep ceph

当然、如果你需要持久挂载,我们可以将 cephfs 挂载的存储信息写入到 /etc/fstab 文件中,例如:
# 永久挂载
:/ /mnt/ceph ceph name=admin,noatime,_netdev 0 2
这样就可以避免机器下次开启可以继续使用了,是不是很简单呢? 确实,除了ceph内核级别的模块之外,Ceph还提供了一个用户空间的 ceph-fuse。在使用之前我们需要安装软件包 ceph-fuse:
# 安装ceph-fuse
yum install ceph-fuse

这里我们采用相同的方法,使用 ceph-fuse 实现文件系统挂载:
# 生成挂载文件目录
mkdir /mnt/cephfs
# 挂载文件系统
ceph-fuse -n client.admin -m 192.168.18.134:6789,192.168.18.135:6789,192.168.18.136:6789 /mnt/cephfs
# 查看挂载状态
df /mnt/cephfs/ -h

从上图我们可以看到此时ceph-fuse自动将cephfs挂载到当前系统中了。CephFS使用是否很简单呢?和NFS的挂载类似,客户端很容易将CephFS文件系统挂载到本地使用,就像本地的目录一样操作CephFS,使用非常便捷。和NFS不太一样的是,CephFS是分布式的文件系统,借助于RADOS的分布式机制,实现高可用,弹性扩展的文件系统。由此,可以实现类似公有云厂商AWS EFS,腾讯云CFS,阿里云NAS文件存储,不失为企业中一个非常好的选择。
4、OSD扩容数据均衡
前面我们还留有一个OSD没有扩容,现在我们继续来看看Ceph的扩容。为了达到负载均衡的效果,我们先往Ceph中写入一些数据,任意往RBD,RGW,或者CephFS中写入数据均可以。为了测试结果,我们往Ceph中写入大量的数据,从而观看数据均衡的效果:
# 准备大文件数据
dd if=/dev/zero of=ceph-test.img bs=1M count=8192

# 向RBD块中写入数据
mount /dev/rbd0 /mnt
cp ceph-test.img /mnt/

#cephfs写入数据
ceph-fuse -n client.admin -m 192.168.18.134:6789,192.168.18.135:6789,192.168.18.136:6789 /mnt/cephfs
cp ceph-test.img /mnt/cephfs/ceph-cephfs.img
#RGW写入数据
s3cmd put ceph-test.img s3://z0ukun-rgw-bucket/ceph-object.img


注:s3cmd put 上传文件一直显示失败:ERROR: S3 error: 416 (InvalidRange)、有知道的小伙伴告诉我一下、谢谢。
此时,Ceph中已写入了大量的数据,扩容的时候PG中包含有大量的数据,需要将数据以PG为单位迁移到新加入的OSD中,我们可以通过ceph df查看当前集群资源池的数据情况:
# 查看集群资源池
ceph df

然后我们将准备好的cephnode-03节点的OSD接入到集群中并观察数据同步的情况,在管理节点上执行ceph-deploy osd create cephnode-03 –data /dev/sdc 命令将其加入到Ceph集群中:
# 测试
ceph-deploy osd create cephnode-03 --data /dev/sdc

此时,我们再次使用 ceph -s 观察集群状态:
# 测试
ceph -s


此时,我们可以看到在pgs中有统计有大量的object处于降级degraded状态,包含103个pgs中的数据需要进行迁移,所以此时可以会看到有很多的一些状态,如peering,remapped,recovery,recovery_wait等状态,在io的下方也可以看到当前集群的读写的速度,包括客户端正常访问的速度和数据恢复recovery的速度。根据集群中数据量的情况,同步的时间有所不同。
当然,需要注意的是,在生产环境中添加节点会涉及大量数据的重分布rebalancing,同步的过程中会涉及到大量的数据读写操作,因此,建议在扩容过程中尽量不要一次性添加太多,避免数据同步的时候影响到线上业务。
好了、到这里关于Ceph分部署集群的所有内容已经全部介绍完了。相信大家对Ceph的整体轮廓非常了解了、感兴趣的同学还可以去查看官网访问关于Ceph更加详细的内容。