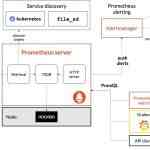
前面介绍了Prometheus的数据指标是通过一个公开的 HTTP(S) 数据接口获取到的,我们不需要单独安装监控的 agent,只需要暴露一个 metrics 接口,Prometheus 就会定期去拉取数据;对于一些普通的 HTTP 服务,我们完全可以直接重用这个服务,添加一个/metrics接口暴露给 Prometheus;而且获取到的指标数据格式是非常易懂的,不需要太高的学习成本。
现在很多服务从一开始就内置了一个/metrics接口,比如 Kubernetes 的各个组件、istio 服务网格都直接提供了数据指标接口。有一些服务即使没有原生集成该接口,也完全可以使用一些 exporter 来获取到指标数据,比如 mysqld_exporter、node_exporter,这些 exporter 就有点类似于传统监控服务中的 agent,作为一直服务存在,用来收集目标服务的指标数据然后直接暴露给 Prometheus。
1、Traefik监控
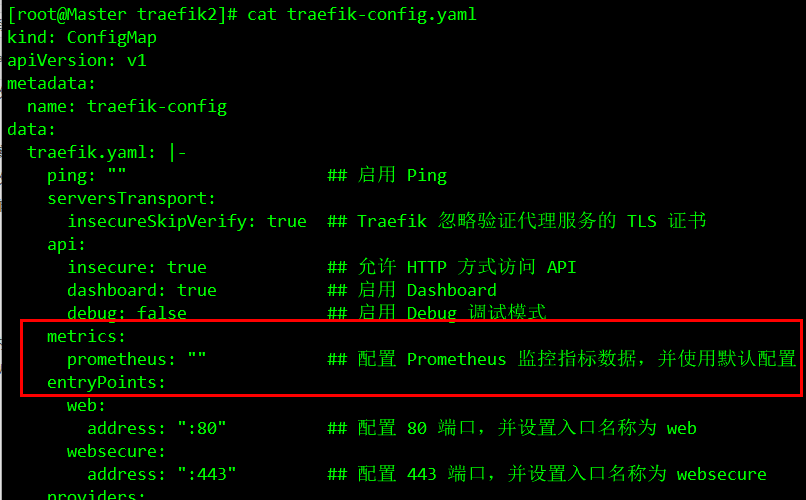
前面我们学习了 ingress 的使用,并采用Traefik作为 ingress-controller,Traefik是 Kubernetes 集群内部服务和外部用户之间的桥梁。Traefik 本身内置了一个/metrics的接口,前面我们安装Traefik的时候默认已经开启了metrics接口(详情请查看文章:Kubernetes外部服务发现-Traefik),这里我们可以直接使用metrics接口获取我们想要的指标数据:
Traefik Pod 运行后,我们可以看到服务 IP:

然后我们可以使用curl检查是否开启了 Prometheus 指标数据接口,或者通过 http://traefik.z0ukun.com/metrics 访问也可以:


注:获取数据的时候小伙伴们一定要耐心等待、数据抓取需要时间(大概1分钟)、我这里可以直接通过域名访问,是因为我在本地配置了hosts。
从上面的截图可以看到 Traefik 的监控数据接口已经开启成功了,然后我们就可以将这个/metrics接口配置到prometheus.yml中去了,直接加到默认的prometheus这个 job 下面(prometheus-cm.yaml):
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
namespace: kube-ops
data:
prometheus.yml: |
global:
scrape_interval: 15s
scrape_timeout: 15s
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
- job_name: 'traefik'
static_configs:
- targets: ['traefik.kube-system.svc.cluster.local:8080'] # 请自行查看本地svc

当然,这里为了方便测试我只是一个很简单的配置,scrape_configs 下面可以支持很多参数,例如:
- basic_auth 和 bearer_token:比如我们提供的/metrics接口需要 basic 认证的时候,通过传统的用户名/密码或者在请求的header中添加对应的 token 都可以支持;
- kubernetes_sd_configs 或 consul_sd_configs:可以用来自动发现一些应用的监控数据。
这里 Traefik 对应的 servicename 是traefik,并且在 kube-system 这个 namespace 下面,所以targets的路径配置则需要使用FQDN的形式:traefik.kube-system.svc.cluster.local,当然如果你的 Traefik 和 Prometheus 都部署在同一个命名空间的话,则直接填 servicename:serviceport即可。然后直接更新这个 ConfigMap 资源对象:
kubectl apply -f prometheus-cm.yaml
现在 Prometheus 的配置文件内容已经更改了,隔一会儿被挂载到 Pod 中的 prometheus.yml 文件也会更新,我们可以执行一个 reload 命令即可让配置生效:
curl -X POST "http://10.102.43.27:9090/-/reload"

注:由于 ConfigMap 通过 Volume 的形式挂载到 Pod 中去的热更新需要一定的间隔时间才会生效,所以需要稍微等一小会儿。
reload 这个 url 是一个 POST 请求,接口重载完成之后我们再去看 Prometheus 的 Dashboard 中查看采集的目标数据:


可以看到我们刚刚添加的traefik这个任务已经出现了,然后同样的我们可以切换到 Graph 下面去,我们可以找到一些 Traefik 的指标数据,至于这些指标数据代表什么意义,一般情况下,我们可以去查看对应的/metrics接口,里面一般情况下都会有对应的注释。 到这里我们就在 Prometheus 上配置了第一个 Kubernetes 应用。
2、export监控应用
前面我们也说过有一些应用可能没有自带/metrics接口供 Prometheus 使用,在这种情况下,我们就需要利用 exporter 服务来为 Prometheus 提供指标数据了。Prometheus 官方为许多应用就提供了对应的 exporter 应用,也有许多第三方的实现,我们可以前往官方网站进行查看:exporters
比如我们这里通过一个redis-exporter 的服务来监控 redis 服务,对于这类应用,我们一般会以 sidecar 的形式和主应用部署在同一个 Pod 中,比如我们这里来部署一个 redis 应用,并用 redis-exporter 的方式来采集监控数据供 Prometheus 使用,如下资源清单文件(prometheus-redis.yaml):
apiVersion: apps/v1
kind: Deployment
metadata:
name: redis
namespace: kube-ops
spec:
selector:
matchLabels:
app: redis
template:
metadata:
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "9121"
labels:
app: redis
spec:
containers:
- name: redis
image: redis:4
resources:
requests:
cpu: 100m
memory: 100Mi
ports:
- containerPort: 6379
- name: redis-exporter
image: oliver006/redis_exporter:latest
resources:
requests:
cpu: 100m
memory: 100Mi
ports:
- containerPort: 9121
---
kind: Service
apiVersion: v1
metadata:
name: redis
namespace: kube-ops
spec:
selector:
app: redis
ports:
- name: redis
port: 6379
targetPort: 6379
- name: prom
port: 9121
targetPort: 9121
注:上⾯我们在 redis 这个 Pod 中包含了两个容器,⼀个就是 redis 本身的主应⽤,另外⼀个容器就是 redis_exporter。现在直接创建上面的应用即可。

创建完成后,我们可以看到 redis 的 Pod 里面包含有两个容器:

我们可以通过 9121 端口来校验是否能够采集到数据:

同样的,现在我们只需要更新 Prometheus 的配置文件:
- job_name: 'redis'
static_configs:
- targets: ['redis.kube-ops.svc.cluster.local:9121']
注:这里targets我们还是采用上面的那种写法。 当然,redis 服务和 Prometheus 处于同一个 namespace,你也可以直接使用 servicename。
这里直接使用kubectl apply -f prometheus-cm.yaml 命令更新配置文件即可,然后重新加载:
# 隔一会儿执行reload操作
curl -X POST "http://10.102.43.27:9090/-/reload"
这个时候我们再去看 Prometheus 的 Dashboard 中查看采集的目标数据:

我们选择任意一个指标,比如redis_exporter_scrapes_total,然后点击执行就可以看到对应的数据图表了:

注:如果时间有问题,需要手动在 Graph 下面调整下时间。
好了、今天的Kubernetes集群监控-集群应用监控到这里就结束啦。后面我们和大家一起来看看如何监控Kubernetes 群集本身。