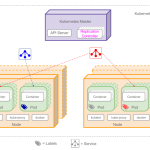
1、什么是HPA?
在前⾯的小节中,我们通过手动执行 kubectl scale 命令或在 Dashboard 上操作可以实现 Pod 的扩缩容,但是这样毕竟需要每次去手动操作,而且业务请求量时间不好判断,所以如果不能自动实现扩缩容也将会比较麻烦。Kubernetes 系统能不能根据 Pod 当前的负载的变化情况自动进行扩缩容呢?
答案当然是可以的。Kubernetes 为我们提供了这样⼀个资源对象: Horizontal Pod Autoscaling (Pod水平自动伸缩),简称 HPA 。 HPA 通过监控分析 RC 或者 Deployment 控制的所有 Pod 的负载变化情况来确定是否需要调整 Pod 的副本数量,这是 HPA 最基本的原理。

HPA 在 kubernetes 集群中被设计成⼀个 controller ,我们可以简单的通过 kubectl autoscale 命令
来创建⼀个 HPA 资源对象, HPA Controller 默认30s轮询⼀次(可通过 kube-controller-manager 的标志 –horizontal-pod-autoscaler-sync-period 进⾏设置),查询指定的资源(RC或者Deployment)中 Pod 的资源使用率,并且与创建时设定的值和指标做对比,从而实现自动伸缩的功能。
当你创建了 HPA 后, HPA 会从 Heapster 或者用户自定义的 RESTClient 端获取每⼀个⼀个 Pod 利用
率或原始值的平均值,然后和 HPA 中定义的指标进行对比,同时计算出需要伸缩的具体值并进行相应的操作。
- Metrics-Server:集群的核心监控数据的聚合器;
- 自定义监控:后面我们会详细讲解自定义监控的方法、这里暂时略过。
2、安装Metrics-Server
kubernetes 集群资源监控之前可以通过 heapster 来获取数据,从 v1.11 开始逐渐废弃 heapster 了,采用 metrics-server 来代替,metrics-server 是集群的核心监控数据的聚合器,它从 kubelet 公开的 Summary API 中采集指标信息,metrics-server 是扩展的 APIServer,依赖于kube-aggregator,因为我们需要在 APIServer 中开启相关参数。
首先我们查看Master节点的 APIServer 参数配置,确保你的 APIServer 启动参数中包含下的一些参数配置:
/etc/kubernetes/manifests/kube-apiserver.yaml
...
- --requestheader-client-ca-file=/etc/kubernetes/certs/proxy-ca.crt
- --proxy-client-cert-file=/etc/kubernetes/certs/proxy.crt
- --proxy-client-key-file=/etc/kubernetes/certs/proxy.key
- --requestheader-allowed-names=aggregator
- --requestheader-extra-headers-prefix=X-Remote-Extra-
- --requestheader-group-headers=X-Remote-Group
- --requestheader-username-headers=X-Remote-User
- --enable-aggregator-routing=true
...

注:如果你没有在 master 节点上运行 kube-proxy,则必须确保 kube-apiserver 启动参数中包含 –enable-aggregator-routing=true
修改完成之后我们就可以直接使用metrics-server 官方提供的资源清单文件进行安装安装,Github项目地址如下(我这里安装的最新版v0.3.6):https://github.com/kubernetes-sigs/metrics-server/tree/v0.3.6/deploy/1.8%2B

难点问题
你可以通过 git clone 命令把代码拉取到本地,但是现在我们还不能去创建Pod,现在还有两个问题需要我们去解决:
1、metrics-server 默认会通过 kubelet 的 10250 端口获取信息,使用的是 hostname,我们部署集群的时候在节点的 /etc/hosts 里面添加了节点的 hostname 和 ip 的映射,但是 metrics-server 的 Pod 内部并没有这个 hosts 信息,当然也就不识别 hostname 了。
2、集群部署的时候,CA 证书并没有把各个节点的 IP 签上去,所以 metrics-server 默认通过 IP 去请求数据时,提示签的证书没有对应的 IP(错误:x509: cannot validate certificate for 172.16.200.1 because it doesn’t contain any IP SANs)。
上面这2个问题官方文档也给出了解决方案、如下:

解决方案
1、为了让集群内部访问集群 hostname 的时候就可以解析到对应的 ip ,我们可以在 metrics-server-0.3.6/deploy/1.8+/metrics-server-deployment.yaml 增加 metrics-server 的启动参数,修改 kubelet-preferred-address-types 参数。
2、CA 证书验证的问题我们可以添加一个 –kubelet-insecure-tls 参数跳过证书校验。
具体修改内容如下:

注:上面的两个问题不解决、Pod创建之后会出现如下故障:
unable to fully collect metrics: [unable to fully scrape metrics from source kubelet_summary:ydzs-master: unable to fetch metrics from kubelet ydzs-master (10.151.30.11): Get https://10.151.30.11:10250/stats/summary/: x509: cannot validate certificate for 10.151.30.11 because it doesn't contain any IP SANs, unable to fully scrape metrics from source kubelet_summary:ydzs-node2: unable to fetch metrics from kubelet ydzs-node2 (10.151.30.23): Get https://10.151.30.23:10250/stats/summary/: x509: cannot validate certificate for 10.151.30.23 because it doesn't contain any IP SANs, unable to fully scrape metrics from source kubelet_summary:ydzs-node1: unable to fetch metrics from kubelet ydzs-node1 (10.151.30.22): Get https://10.151.30.22:10250/stats/summary/: x509: cannot validate certificate for 10.151.30.22 because it doesn't contain any IP SANs]
unable to fully collect metrics: [unable to fully scrape metrics from source kubelet_summary:ydzs-node2: unable to fetch metrics from kubelet ydzs-node2 (ydzs-node2): Get https://ydzs-node2:10250/stats/summary/: dial tcp: lookup ydzs-node2 on 10.96.0.10:53: no such host, unable to fully scrape metrics from source kubelet_summary:ydzs-master: unable to fetch metrics from kubelet ydzs-master (ydzs-master): Get https://ydzs-master:10250/stats/summary/: dial tcp: lookup ydzs-master on 10.96.0.10:53: no such host, unable to fully scrape metrics from source kubelet_summary:ydzs-node1: unable to fetch metrics from kubelet ydzs-node1 (ydzs-node1): Get https://ydzs-node1:10250/stats/summary/: dial tcp: lookup ydzs-node1 on 10.96.0.10:53: no such host]
现在我们就可以进入到metrics-server-0.3.6/deploy/1.8+目录通过 kubectl apply -f . 命令创建Pod了;当然、安装之前你还需要提前把镜像 metrics-server 需要的镜像拉取到每个Node节点上(这里请各位小伙伴自行到hub仓库去拉取、拉取完成以后打上如下标签:k8s.gcr.io/metrics-server-amd64:v0.3.6):

安装完成以后我们可以通过 kubectl get pods -n kube-system 查看 metrics-server 的状态已经 running 了,稍等片刻之后我们可以通过 kubectl top nodes 命令查看Node 的CPU和内存使用量:


当然、我们也可以通过Dashboard去查看 Pod 的CPU和内存使用量:

2、HPA自动扩缩容
操作完上面的所有内容之后、我们就可以来创建⼀个 Deployment 管理的 Nginx Pod,然后利用 HPA 进行自动扩缩容。我们同样还是通过示例的方式来进行,首先我们来定义 Deployment 的 Yaml 文件(hpa-deploy-demo.yaml),如下:
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: hpa-demo
labels:
app: hpa
spec:
replicas: 1 #副本数量
revisionHistoryLimit: 15 #rs记录保留数量
minReadySeconds: 5
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
resources:
requests:
cpu: 100m #CPU资源请求大小
ports:
- containerPort: 80

然后我们创建 Deployment,创建完成之后并查看Pod的状态。现在我们就可以使用 kubectl autoscale 命令来创建 HPA 了:
kubectl autoscale deployment hpa-demo --cpu-percent=1 --min=1 --max=10
注:此命令创建了⼀个关联资源 hpa-nginx-deploy 的 HPA ,最小的 Pod 副本数为1,最大副本数为10。 HPA 会根据设定的 cpu 使用率(1%)动态的增加或者减少Pod数量(这里为了快速看到测试效果、我把 cpu 使用率调的很低、因为服务器处理太快了)。执行完成之后我们通过 kubectl get hpa 命令查看 HPA 的状态:

当然除了使用 kubectl autoscale 命令来创建HPA外,我们还可以通过创建 Yaml 文件的形式来创建 HPA 资源对象。如果我们不知道怎么编写的话,可以查看上⾯命令行创建的 HPA 的 Yaml 文件:

# 配置参考:
maxReplicas: 10 //资源最大副本数
minReplicas: 1 //资源最小副本数
scaleTargetRef:
apiVersion: extensions/v1
kind: Deployment //需要伸缩的资源类型
name: nginxtest //需要伸缩的资源名称
targetCPUUtilizationPercentage: 1 //触发伸缩的cpu使⽤率
status:
currentCPUUtilizationPercentage: 0 //当前资源下pod的cpu使用率
currentReplicas: 1 //当前的副本数
desiredReplicas: 1 //期望的副本数
我们可以根据上面的参考 Yaml 文件就可以自己来创建⼀个基于 Yaml 的 HPA 描述⽂件了。
3、压力测试
现在我们来增大负载金星测试,我们来创建⼀个 busybox ,并且循环访问上⾯创建的服务;我们通过 kubectl run -i –tty load-generator –image=busybox /bin/sh 命令创建2个busybox容器、然后进入busybox的/bin/sh命令行,再通过 while true; do wget -q -O- http://10.244.2.38; done 命令循环访问 hpa-demo(IP地址可以通过describe命令查到)的80端口实现压力测试:

这里我们为了快速看到效果、我们同时开2个终端、分别进入不同的 busybox 同时进行压力测试,压力测试开始之后我们可以通过 kubectl get hpa 命令看到、hpa-demo 的CPU使用率暴增;metrics-server 检测到CPU暴增之后,HPA开始自动扩容Pod数量,HPA已经开始工作了 :



同时我们查看相关资源hpa-demo的副本数量,很快Pod的数量开始达到我们配置的最大副本数量10,当然我们也可以通过Dashboard很直观的看到Pod调度情况:


然后我们停止压力测试,耐心等待⼀段时间观察下 HPA 和 Deployment 对象,CPU使用率开始下降、Pod副本数量又从10变成了1:


不过当前的 HPA 只有 CPU 使⽤率这⼀个指标,还不是很灵活的,在后⾯我们来根据自定义的监控自动对 Pod 进行扩缩容。