文章目录
前面我们通过Ceph-Deploy工具快速部署了分布式存储Ceph、今天我们一起来看看、如果通过Rook业务编排工具把Ceph运行在Kubernetes集群中。前面其实我们详细的讲解过关于Ceph的特点、Ceph的架构和Ceph的关键组件、感兴趣的同学也可以去看看官方文档:Ceph ;这里我们再来简单的回顾一下。
一般来说无状态服务有利于服务横向扩容,但是现实中很难做到服务完全无状态化,像数据库、缓存等这些服务数据需要持久化,一定是有状态的,要想让这些服务也能运行在Kubernetes集群中就必须先解决数据持久化问题。如果你的Kubernetes集群是运行在AWS、阿里云等公有云上这个问题很好解决,直接使用云厂商提供的EBS等弹性云存储就行,但如果是运行在私有云上就需要自建分布存储。
Ceph是一个兼具良好性能、可靠性和可扩展性的分布式存储系统,它支持的块存储类型具有较好的性能,且kernel自带rbd模块,很适合拿来做为kubernetes的后端持久化存储。但是Ceph学习曲线陡峭,想要快速搭建一套集群不是很容易,运维成本也比较高,所以才催生出了Rook这样的项目,来简化Ceph的搭建和维护成本。
Rook 由最开始的只专注Ceph的编排工具发展成现在支持多种存储方案的一个开源的云原生存储编排平台,提供对各种存储方案的编排支持,以方便和云原生环境进行本地集成。 Rook通过自动化部署、启动、配置、供应、扩展、升级、迁移、灾难恢复、监控和资源管理来将存储软件转变成能实现自我管理、自我扩展和自我修复的存储服务,降低使用门槛。
1、Ceph特点
高性能
- 抛弃了传统的集中式存储运输局寻址的方案,采用 CRUSH 算法,数据分布均衡,并行度高;
- 考虑了容灾域的隔离,能够实现各类负载的副本设置规则,例如跨机房、机架感知等;
- 能够支持上千个存储节点的规模,支持 TB 到 PB 级的数据;
高可用性
- 副本数可以灵活控制;
- 支持故障域分离,数据强一致性;
- 多种故障场景自动进行修复自愈;
- 没有单点故障,自动管理;
高可扩展性
- 去中心化;
- 扩展灵活;
- 随着节点增加而线性增长;
特性丰富
- 支持三种存储接口:块存储、文件存储、对象存储;
- 支持自定义接口,支持多种语言驱动;
2、Ceph架构
支持三种接口
- Object:有原生 API,而且也兼容 Swift 和 S3 的 API;
- Block:支持精简配置、快照、克隆;
- File:Posix 接口,支持快照;
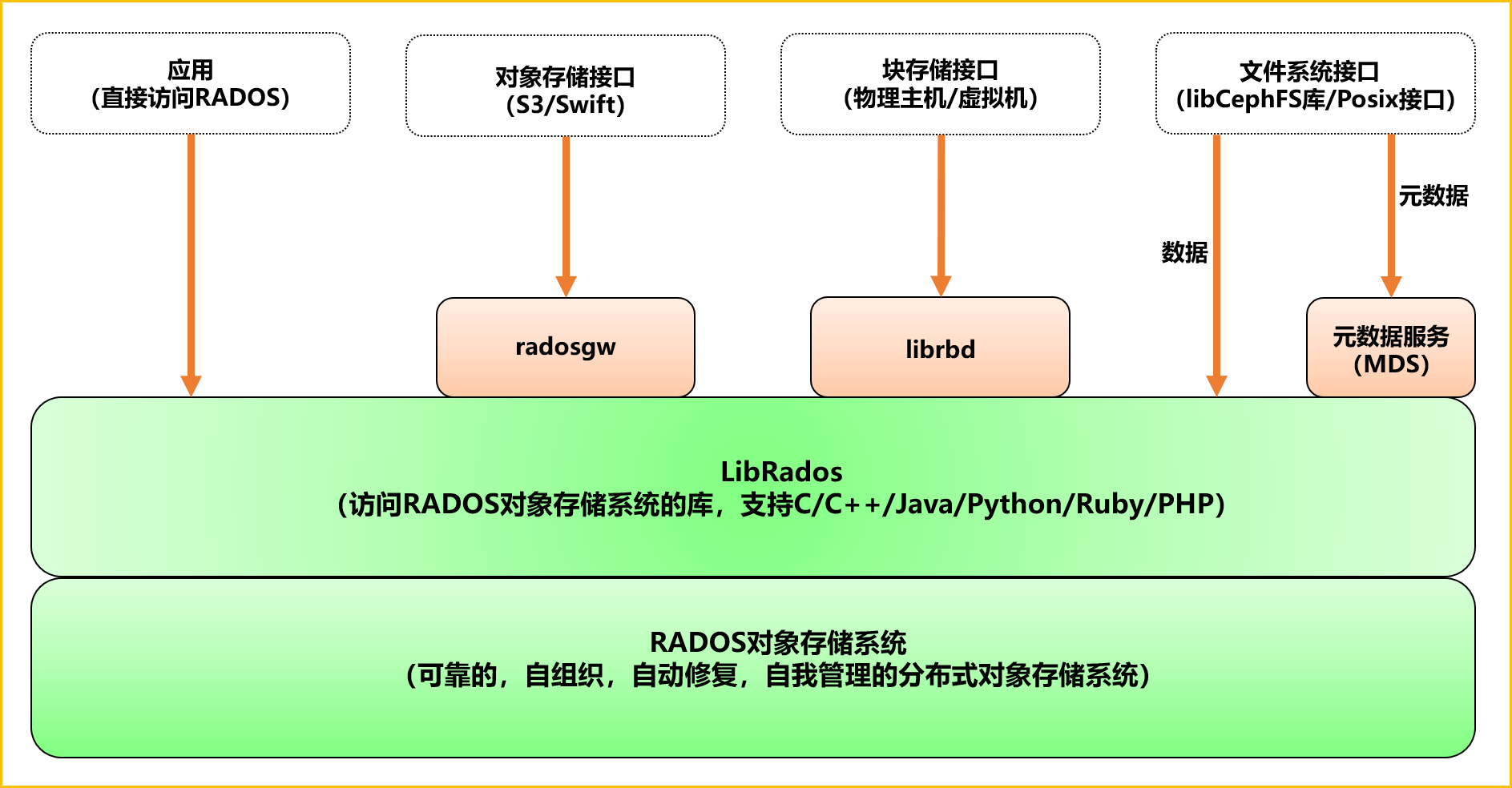
3、Ceph组件
Monitor:一个 Ceph 集群需要多个 Monitor 组成的小集群,它们通过 Paxos 同步数据,用来保存 OSD 的元数据。
OSD:全称 Object Storage Device,也就是负责响应客户端请求返回具体数据的进程,一个 Ceph 集群一般都有很多个 OSD。主要功能用于数据的存储,当直接使用硬盘作为存储目标时,一块硬盘称之为 OSD,当使用一个目录作为存储目标的时候,这个目录也被称为 OSD。
MDS:全称 Ceph Metadata Server,是 CephFS 服务依赖的元数据服务,对象存储和块设备存储不需要该服务。
Object:Ceph 最底层的存储单元是 Object 对象,一条数据、一个配置都是一个对象,每个 Object 包含 ID、元数据和原始数据。
Pool:Pool 是一个存储对象的逻辑分区,它通常规定了数据冗余的类型与副本数,默认为3副本。对于不同类型的存储,需要单独的 Pool,如 RBD。
PG:全称 Placement Grouops,是一个逻辑概念,一个 OSD 包含多个 PG。引入 PG 这一层其实是为了更好的分配数据和定位数据。每个 Pool 内包含很多个 PG,它是一个对象的集合,服务端数据均衡和恢复的最小单位就是 PG。

- pool 是 ceph 存储数据时的逻辑分区,它起到 namespace 的作用;
- 每个 pool 包含一定数量(可配置)的 PG;
- PG 里的对象被映射到不同的 Object 上;
- pool 是分布到整个集群的;
FileStore与BlueStore:FileStore 是老版本默认使用的后端存储引擎,如果使用 FileStore,建议使用 xfs 文件系统。BlueStore 是一个新的后端存储引擎,可以直接管理裸硬盘,抛弃了 ext4 与 xfs 等本地文件系统。可以直接对物理硬盘进行操作,同时效率也高出很多。
RADOS:全称 Reliable Autonomic Distributed Object Store,是 Ceph 集群的精华,用于实现数据分配、Failover 等集群操作。
Librados:Librados 是 Rados 提供库,因为 RADOS 是协议很难直接访问,因此上层的 RBD、RGW 和 CephFS 都是通过 librados 访问的,目前提供 PHP、Ruby、Java、Python、C 和 C++ 支持。
CRUSH:CRUSH 是 Ceph 使用的数据分布算法,类似一致性哈希,让数据分配到预期的地方。 RBD:全称 RADOS Block Device,是 Ceph 对外提供的块设备服务,如虚拟机硬盘,支持快照功能。
RGW:全称是 RADOS Gateway,是 Ceph 对外提供的对象存储服务,接口与 S3 和 Swift 兼容。
CephFS:全称 Ceph File System,是 Ceph 对外提供的文件系统服务。
4、Ceph存储接口
块存储:例如,磁盘阵列,硬盘,主要是将裸磁盘空间映射给主机使用的。
优点
- 通过 Raid 与 LVM 等手段,对数据提供了保护。
- 多块廉价的硬盘组合起来,提高容量。
- 多块磁盘组合出来的逻辑盘,提升读写效率。
缺点
- 采用 SAN 架构组网时,光纤交换机,造价成本高。
- 主机之间无法共享数据。
使用场景
- Docker 容器、虚拟机磁盘存储分配。
- 日志存储
- 文件存储
- …
文件存储:例如,FTP、NFS 服务器,为了克服块存储文件无法共享的问题,所以有了文件存储,在服务器上架设 FTP 与 NFS 服务器,就是文件存储。
优点
- 造价低,随便一台机器就可以了
- 方便文件可以共享
缺点
- 读写速率低
- 传输速率慢
使用场景
- 日志存储
- 有目录结构的文件存储
- …
对象存储:例如,内置大容量硬盘的分布式服务器(swift, s3);多台服务器内置大容量硬盘,安装上对象存储管理软件,对外提供读写访问功能。
优点
- 具备块存储的读写高速。
- 具备文件存储的共享等特性
使用场景:(适合更新变动较少的数据)
- 图片存储
- 视频存储
-
…
5、Ceph部署
由于我们这里在 Kubernetes 集群中使用,也为了方便管理,我们使用 Rook 来部署 Ceph 集群,Rook 是一个开源的云原生存储编排工具,提供平台、框架和对各种存储解决方案的支持,以和云原生环境进行本地集成。
Rook 将存储软件转变成自我管理、自我扩展和自我修复的存储服务,通过自动化部署、启动、配置、供应、扩展、升级、迁移、灾难恢复、监控和资源管理来实现。Rook 底层使用云原生容器管理、调度和编排平台提供的能力来提供这些功能,其实就是我们平常说的 Operator。Rook 利用扩展功能将其深度集成到云原生环境中,并为调度、生命周期管理、资源管理、安全性、监控等提供了无缝的体验。有关 Rook 当前支持的存储解决方案的状态的更多详细信息,可以参考 Rook 仓库 的项目介绍。
Rook官方网站:https://rook.io/
Rook仓库:https://github.com/rook/rook/blob/master/README.md#project-status

5.1、Ceph环境
Rook Ceph 需要使用 RBD 内核模块,我们可以通过运行 modprobe rbd 来测试 Kubernetes 节点是否有该模块,如果没有,则需要更新下内核版本。 另外需要在节点上安装 lvm2 软件包:
# Centos 安装 lvm2
sudo yum install -y lvm2
# Ubuntu 安装 lvm2
sudo apt-get install -y lvm2
5.2、部署Rook Operator
Rook默认会使用所有节点上的所有资源,Rook Operator自动在所有节点上启动OSD设备。当然,我们也可以也可以通过修改配置文件,指定哪些节点或者哪些设备会被识别并使用使用。在开始之前我们先给每个节点主机添加一块500G的新磁盘:/dev/sdb,作为OSD盘,提供存储空间,添加完成后扫描磁盘,确保主机能够正常识别到:
# 扫描 SCSI总线并添加 SCSI 设备
for host in $(ls /sys/class/scsi_host) ; do echo "- - -">/sys/class/scsi_host/$host/scan; done
# 重新扫描 SCSI 总线
for $scsi_device in (ls /sys/class/scsi_device/); do echo 1>/sys/class/scsi_device/$scsi_device/device/rescan; done
# 查看已添加的磁盘
lsblk
我们这里部署的 release-1.2.7 版本的 Rook Operator,我们用git clone命令从下面的Github仓库中把 Rook Operator 的资源文件下载到本地。
Github地址:https://github.com/rook/rook.git
资源清单:https://github.com/rook/rook/tree/v1.2.7/cluster/examples/kubernetes/ceph

# 下载资源文件(这里我们通过-b命令指定分支版本)
git clone https://github.com/rook/rook.git -b v1.2.7
# 进入资源清单文件目录
cd rook/cluster/examples/kubernetes/ceph/
# 安装CRD、RBAC相关资源对象
kubectl apply -f common.yaml
# 安装 rook operator
kubectl apply -f operator.yaml
注:这里需要说明一下、我们在执行operator的创建之前、要先确认一下ROOK_CSI_KUBELET_DIR_PATH的路径地址。因为默认的kubelet安装地址是/var/lib/kubelet,这里因为我们在安装的过程中把组件数据路径修改为/data/k8s/k8s/kubelet,这里一定要和集群部署时候的路径一致,不然会出现下面的报错信息而导致PVC无法正常挂载。
ROOK_CSI_KUBELET_DIR_PATH: "/var/lib/kubelet"
ROOK_CSI_KUBELET_DIR_PATH: "/data/k8s/k8s/kubelet"
kubernetes.io/csi: attacher.MountDevice failed to create newCsiDriverClient: driver name rook-ceph.rbd.csi.ceph.com not found in the list of registered CSI drivers
我们依次执行上面的命令,通过 common.yaml和operator.yaml 资源文件创建CRD、RBAC和Rook Operator资源对象。执行完成之后我们来验证一下 rook-ceph-operator 是否处于“Running”状态:
# 验证 rook-ceph 状态
kubectl get pods -n rook-ceph

从上图我们可以看到 Rook Operator 运行成功后,还会有一个 DaemonSet 控制器运行得 rook-discover 应用,当 Rook Operator 处于 Running 状态,然后我们就可以创建 Ceph 集群了。为了使集群在重启后不受影响,请确保设置的 dataDirHostPath 属性值为有效得主机路径。更多相关设置,同学们可以查看官方文档:集群配置相关文档。
注:安装过程中不要着急、可能后端是在拉取镜像;各服务之间也有先后顺序的依赖关系正在运行,所以千万不要着急。
然后我们创建 CephCluster 资源对象,创建 CephCluster 资源对象有两种方式;如果你是测试环境或者是预生产环境,我们可以采用上面下载的资源清单文件中提供的 cluster-test.yaml 文件;如果你是正式生产环境则需要使用 cluster.yaml 资源文件。
apiVersion: ceph.rook.io/v1
kind: CephCluster
metadata:
name: rook-ceph
namespace: rook-ceph
spec:
cephVersion:
image: ceph/ceph:v14.2.7
allowUnsupported: true
dataDirHostPath: /var/lib/rook
skipUpgradeChecks: false
continueUpgradeAfterChecksEvenIfNotHealthy: false
mon:
count: 1
allowMultiplePerNode: true
dashboard:
enabled: true
ssl: true
monitoring:
enabled: false # requires Prometheus to be pre-installed
rulesNamespace: rook-ceph
network:
hostNetwork: false
rbdMirroring:
workers: 0
crashCollector:
disable: false
mgr:
modules:
# the pg_autoscaler is only available on nautilus or newer. remove this if testing mimic.
- name: pg_autoscaler
enabled: true
storage:
useAllNodes: true
useAllDevices: false
config:
databaseSizeMB: "1024" # this value can be removed for environments with normal sized disks (100 GB or larger)
journalSizeMB: "1024" # this value can be removed for environments with normal sized disks (20 GB or larger)
osdsPerDevice: "1" # this value can be overridden at the node or device level
directories:
- path: /var/lib/rook
# nodes:
# - name: "minikube"
# directories:
# - path: "/data/rook-dir"
# devices:
# - name: "sdb"
# - name: "nvme01" # multiple osds can be created on high performance devices
# config:
# osdsPerDevice: "5"
上面有几个比较重要的字段需要重点说明一下:
dataDirHostPath:宿主机上的目录,用于每个服务存储配置和数据。如果目录不存在,会自动创建该目录。由于此目录在主机上保留,因此在删除 Pod 后将保留该目录,另外不得使用以下路径及其任何子路径:/etc/ceph、/rook 或 /var/log/ceph;
useAllNodes:用于表示是否使用集群中的所有节点进行存储,如果在 nodes 字段下指定了各个节点,则必须将useAllNodes设置为 false;
useAllDevices:表示 OSD 是否自动使用节点上的所有设备,一般设置为 false,这样可控性较高;
directories:一般来说应该使用一块裸盘来做存储,有时为了测试方便,使用一个目录也是可以的,当然生成环境不推荐使用目录。
除了上面这些字段属性之外还有很多其他可以细粒度控制的参数,同学们可以查看官方文档:集群配置相关文档。我们可以自定义集群信息,例如我们将下面的文件添加到 cluster.yaml 文件中,也可以不添加直接使用默认配置。如果没有自定义集群信息,则Rook-Ceph会自动完成配置,执行下面的命令创建 CephCluster 集群:
storage:
useAllNodes: false # 不使用所有节点(指定节点)
useAllDevices: false # 不使用所有的设备(指定设备)
location:
config:
storeType: bluestore # 指定类型为裸磁盘
# 使用单独的裸盘作为ceph存储,指定kubernetes节点名称以及要使用的裸盘名称
nodes:
- name: "kubernetes-01" # 指定存储节点主机
devices:
- name: "sdb" # 指定磁盘为sdb
- name: "kubernetes-02" # 指定存储节点主机
devices:
- name: "sdb" # 指定磁盘为sdb
- name: "kubernetes-03" # 指定存储节点主机
devices:
- name: "sdb" # 指定磁盘为sdb
# 创建cluster资源对象
kubectl apply -f cluster.yaml

创建完成后,Rook Operator 就会根据我们的描述信息去自动创建 Ceph 集群了。如果部署失败,我们需要在所有节点执行如下清理操作;清理完成之后从第一部开始重新创建:
# 进入资源清单文件目录
cd rook/cluster/examples/kubernetes/ceph/
# 删除上面创建的所有资源对象
kubectl delete -f .
# 在所有节点执行下面的清除命令
rm -rf /var/lib/rook
/dev/mapper/ceph-*
dmsetup ls
dmsetup remove_all
dd if=/dev/zero of=/dev/sdb bs=512k count=1
wipefs -af /dev/sdb
# 如果发现有删除不掉的资源对象可以通过下面的命令强制删除
# 删除POD
kubectl delete pod PODNAME --force --grace-period=0
# 删除NAMESPACE
kubectl delete namespace NAMESPACENAME --force --grace-period=0
# 如果上面的命令无法强制删除namespace资源对象我们可以使用下面的工具删除
yum install jq culr -y
git clone https://github.com/ctron/kill-kube-ns.git
cd kill-kube-ns && ./kill-kube-ns {要删除的namespace}
5.3、Ceph 集群验证
要验证集群是否处于正常状态,我们可以使用 Rook 工具箱 来运行 ceph status 命令查看。Rook 工具箱是一个用于调试和测试 Rook 的常用工具容器,该工具基于 CentOS 镜像,所以可以使用 yum 来轻松安装更多的工具包。我们这里用 Deployment 控制器来部署 Rook 工具箱,部署的资源清单文件是 toolbox.yaml。我们直接创建这个 Pod:
# 创建 toolbox 资源对象
kubectl apply -f toolbox.yaml

我们从上面的截图可以看到 csi-cephfsplugin-* 、csi-rbdplugin-*相关的几个Pod一直处于 ContainerCreating 状态、我们通过 describe 命令查看一下详细状态:

这里提示我们 hostPath type check failed: /var/lib/kubelet/pods is not a directory;hostPath type check failed: /var/lib/kubelet/plugins_registry/ is not a directory 等信息。这里因为rook-ceph自动创建 csi 相关的插件目录失败、需要我们手动去创建一下下面这几个目录:
mkdir -p /var/lib/kubelet/pods
mkdir /var/lib/kubelet/plugins_registry/
mkdir -p /var/lib/kubelet/plugins/rook-ceph.cephfs.csi.ceph.com/

创建完成以后,我们重新查看Pod状态:

我们可以看到、此时上面几个Pod开始初始化,并完成安装一直到 running。一旦 toolbox 的 Pod 运行成功后,我们就可以使用下面的命令进入到工具箱内部进行操作:
# 进入 toolbox 工具箱 Pod 内部进行相关操作
kubectl -n rook-ceph exec -it $(kubectl -n rook-ceph get pod -l "app=rook-ceph-tools" -o jsonpath='{.items[0].metadata.name}') bash
工具箱中的所有可用工具命令均已准备就绪,可满足您的故障排除需求。例如:
# 查看 Ceph 状态
ceph status
ceph -s
# 查看 OSD 状态
ceph osd status
ceph osd df
ceph osd utilization
ceph osd pool stats
ceph osd tree
# 查看 Ceph 容量
ceph df
# 查看 Rados 状态
rados df
# 查看PG状态
ceph pg stat

如果现在我们要查看集群的状态,需要满足下面的条件才会认为集群是健康的:
- 所有 mons 应该达到法定数量;
- mgr 应该是激活状态;
- 至少有一个 OSD 处于激活状态;
- 如果不是 HEALTH_OK 状态,则应该查看告警或者错误信息;
如果群集运行不正常,我们可以查看 Ceph 常见问题 以了解更多详细信息和可能的解决方案。当然、你也可以把集群全部删除并清理掉缓存文件然后重新安装。
5.4、Ceph Dashboard
Ceph 有一个 Dashboard 工具,我们可以在上面查看集群的状态,包括总体运行状态,mgr、osd 和其他 Ceph 进程的状态,查看池和 PG 状态,以及显示守护进程的日志等等。
我们可以在上面的 cluster CRD 对象中开启 dashboard,设置dashboard.enable=true即可,这样 Rook Operator 就会启用 ceph-mgr dashboard 模块,并将创建一个 Kubernetes Service 来暴露该服务,将启用端口 7000 进行 https 访问,如果 Ceph 集群部署成功了,我们可以使用下面的命令来查看 Dashboard 的 Service:
# 查看 rook-ceph 的 Service
kubectl get svc -n rook-ceph

这里的 rook-ceph-mgr 服务用于报告 Prometheus metrics 指标数据的,而后面的的 rook-ceph-mgr-dashboard 服务就是我们的 Dashboard 服务,如果在集群内部我们可以通过 DNS 名称 https://rook-ceph-mgr-dashboard.rook-ceph:8443或者 CluterIP https://10.254.145.368443 来进行访问,但是如果要在集群外部进行访问的话,我们就需要通过 Ingress 或者 NodePort 类型的 Service 来暴露了。这里我们还是通过 Traefik Ingress 服务来访问 Dashboard,我们自定义资源清单文件(ceph-dashboard-ingress-route.yaml),然后直接创建即可:
apiVersion: traefik.containo.us/v1alpha1
kind: IngressRoute
metadata:
name: rook-ceph-mgr-dashboard
namespace: rook-ceph
spec:
entryPoints:
- websecure
routes:
- match: Host(`ceph.z0ukun.com`)
kind: Rule
services:
- name: rook-ceph-mgr-dashboard
port: 8443
tls:
certResolver: default
创建完成后我们直接通过ceph.z0ukun.com这个域名来访问Ceph服务(记得修改本地hosts文件):

但是在访问的时候需要我们登录才能够访问,Rook 创建了一个默认的用户 admin,并在运行 Rook 的命名空间中生成了一个名为 rook-ceph-dashboard-admin-password 的 Secret,我们可以运行下面的命令获取密码:
# 获取Ceph登录密码
kubectl -n rook-ceph get secret rook-ceph-dashboard-password -o jsonpath="{['data']['password']}" | base64 --decode && echo
用上面获得的密码和用户名 admin 就可以登录 Dashboard 了,在 Dashboard 上面可以查看到整个集群的状态:

5.5、Ceph 使用
现在我们已经把 Ceph 集群搭建成功了,下面就可以来使用 Ceph 存储了。首先我们需要创建存储池,我们可以用 CRD 来定义 Pool。Rook 提供了两种机制来维持 OSD:
- 副本:缺省选项,每个对象都会根据 spec.replicated.size 在多个磁盘上进行复制。建议非生产环境至少 2 个副本,生产环境至少 3 个。
- Erasure Code:是一种较为节约的方式。EC 把数据拆分 n 段(spec.erasureCoded.dataChunks),再加入 k 个代码段(spec.erasureCoded.codingChunks),用分布的方式把 n+k 段数据保存在磁盘上。这种情况下 Ceph 能够隔离 k 个 OSD 的损失。
我们这里使用副本的方式,创建 RBD 类型的存储池。前面我们下载的资源清单文件中包含一个RBD类型存储池资源文件(pool.yaml):
apiVersion: ceph.rook.io/v1
kind: CephBlockPool
metadata:
name: replicapool # operator会监听并创建一个pool,执行完后界面上也能看到对应的pool
namespace: rook-ceph
spec:
failureDomain: host # 数据块的故障域: 值为host时,每个数据块将放置在不同的主机上;值为osd时,每个数据块将放置在不同的osd上
replicated:
size: 3 # 池中数据的副本数,1就是不保存任何副本
我们直接创建上面的资源对象即可;存储池创建完成后我们在 Dashboard 上面的确可以看到新增了一个 pool:

我们也可以进入 toolbox 资源对象中查看Ceph状态:

如果发现集群健康状态变成了 WARN,可以查看 Dashboard 上的错误日志。上面我们做了3副本的配置,如果有4个 osd 的时候,每个 osd 上均分了8/4 *3=6个pgs,会出现错误:Health check update: too few PGs per OSD (6 < min 30) (TOO_FEW_PGS),集群这种状态如果进行数据的存储和操作,会卡死,无法响应io,同时会导致大面积的 osd down。这种情况可以进入 toolbox 的容器中查看上面存储的 pg 数量:
# 查看 replicapool pg_num数量
ceph osd pool get replicapool pg_num
# 设置 replicapool pg_num数量
ceph osd pool set replicapool pg_num 64
注:不过需要注意的是这里的 pool 上没有数据,所以修改 pg 影响并不大,但是如果是生产环境重新修改 pg 数,会对生产环境产生较大影响。因为 pg 数变了,就会导致整个集群的数据重新均衡和迁移,数据越大响应 io 的时间会越长。所以,最好在一开始就设置好 pg 数。
现在我们来创建一个 StorageClass 来进行动态存储配置,如下所示我们定义一个 Ceph 的块存储的 StorageClass:(storageclass.yaml)
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: rook-ceph-block
provisioner: rook-ceph.rbd.csi.ceph.com
parameters:
# clusterID 是 rook 集群运行的命名空间
clusterID: rook-ceph
# 指定存储池
pool: replicapool
# RBD image (实际的存储介质) 格式. 默认为 "2".
imageFormat: "2"
# RBD image 特性. CSI RBD 现在只支持 `layering` .
imageFeatures: layering
# Ceph 管理员认证信息,这些都是在 clusterID 命名空间下面自动生成的
csi.storage.k8s.io/provisioner-secret-name: rook-csi-rbd-provisioner
csi.storage.k8s.io/provisioner-secret-namespace: rook-ceph
csi.storage.k8s.io/node-stage-secret-name: rook-csi-rbd-node
csi.storage.k8s.io/node-stage-secret-namespace: rook-ceph
# 指定 volume 的文件系统格式,如果不指定, csi-provisioner 会默认设置为 `ext4`
csi.storage.k8s.io/fstype: ext4
# uncomment the following to use rbd-nbd as mounter on supported nodes
# **IMPORTANT**: If you are using rbd-nbd as the mounter, during upgrade you will be hit a ceph-csi
# issue that causes the mount to be disconnected. You will need to follow special upgrade steps
# to restart your application pods. Therefore, this option is not recommended.
#mounter: rbd-nbd
reclaimPolicy: Delete
直接创建上面的 StorageClass 资源对象,创建完成以后我们可以查看 storageclass 资源对象创建情况:

然后创建一个 PVC 来使用上面的 StorageClass 对象:(pvc.yaml)
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mysql-pv-claim
labels:
app: wordpress
spec:
storageClassName: rook-ceph-block
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 20Gi

创建完成后我们可以看到我们的 PVC 对象已经是 Bound 状态了,自动创建了对应的 PV,然后我们就可以直接使用这个 PVC 对象来做数据持久化操作了。
在官方仓库 cluster/examples/kubernetes 目录下,官方给了个 wordpress 的例子,可以直接运行测试即可:
$ kubectl apply -f mysql.yaml
$ kubectl apply -f wordpress.yaml

当应用都处于 Running 状态后,我们可以通过 http://<任意节点IP>:31278 去访问 wordpress 应用。

Muchas gracias. ?Como puedo iniciar sesion?