1、什么是探针
上一节我们详细讲解了 Pod 中容器生命命周期的两个钩子函数, PostStart 与 PreStop ,其中 PostStart 是在容器创建后立即执⾏的,而PreStop 这个钩⼦函数则是在容器终止之前执⾏的。除了上⾯这两个钩⼦函数以外,还有⼀项配置会影响到容器的⽣命周期的,那就是健康检查的探针。
在 Kubernetes 集群当中,我们可以通过配置 liveness probe (存活探针)和 readiness probe (可读性探针)来影响容器的⽣存周期。
- kubelet 通过使⽤ liveness probe 来确定你的应⽤程序是否正在运⾏,通俗点将就是是否还活着。⼀般来说,如果你的程序⼀旦崩溃了, Kubernetes 就会立刻知道这个程序已经终⽌了,然后就会重启这个程序。而 liveness probe 的目的就是来捕获到当前应⽤程序是否终止,是否崩溃,如果出现了这些情况,那么就重启处于该状态下的容器,使应⽤程序在存在 bug 的情况下依然能够继续运⾏下去。
- kubelet 使⽤ readiness probe 来确定容器是否已经就绪可以接收流量过来了。探针通俗点讲就是:是否准备好了,现在可以开始⼯作了。只有当 Pod 中的容器都处于就绪状态的时候 kubelet 才会认定该 Pod 处于就绪状态,因为⼀个 Pod 下⾯可能会有多个容器。当然 Pod 如果处于⾮就绪状态,那么我们就会将他从我们的⼯作队列(实际上就是我们后⾯需要重点学习的 Service)中移除出,这样我们的流量就不会被路由到这个 Pod ⾥⾯来了。
探针的⽀持两种配置⽅式:
- exec:执⾏⼀段命令
- http:检测某个 http 请求
- tcpSocket:使⽤此配置, kubelet 将尝试在指定端⼝上打开容器的套接字。如果可以建⽴连接,容器被认为是健康的,如果不能就认为是失败的。(实际上就是检查端⼝)
2、存活探针
这⾥需要⽤⼀个新的属性: livenessProbe ,下⾯通过 exec 执⾏⼀段命令,其中 periodSeconds 属性表示让 kubelet 每隔5秒执⾏⼀次存活探针,也就是每5秒执⾏⼀次上⾯的 cat /tmp/healthy 命令。如果命令执⾏成功了将返回0,那么 kubelet 就会认为当前这个容器是存活的并且很监控,如果返回的是⾮0值,那么 kubelet 就会把该容器杀掉然后重启它。
另外⼀个属性 initialDelaySeconds 表示在第⼀次执⾏探针的时候要等待5秒,这样能够确保我们的容器能够有⾜够的时间启动起来。如果第⼀次执⾏探针等候的时间太短,很有可能容器还没正常启动起来,所以存活探针很可能始终都是失败的,这样就会⽆休⽌的重启下去了形成死循环,所以⼀个合理的 initialDelaySeconds ⾮常重要。
通过exec监测livenessProbe
我们还是通过一个Yaml示例来看看存活探针的使用方法,⾸先我们⽤ exec 执⾏命令的方式来检测容器的存活,如下:
apiVersion: v1
kind: Pod
metadata:
name: liveness-exec
labels:
test: liveness
spec:
containers:
- name: liveness
image: busybox
args:
- /bin/sh
- -c
- touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5
periodSeconds: 5
注:我们在容器启动的时候,执⾏了如下 /bin/sh -c “touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600” 命令;在容器最开始的30秒内有⼀个 /tmp/healthy ⽂件,在这30秒内执⾏ cat /tmp/healthy 命令都会返回⼀个成功的返回码。30秒后,我们删除这个⽂件,然后执⾏ cat /tmp/healthy 就会失败了,这个时候就会重启容器了。
我们创建Pod后,在30秒内,查看Pod的 Event:
kubectl describe pod liveness-exec
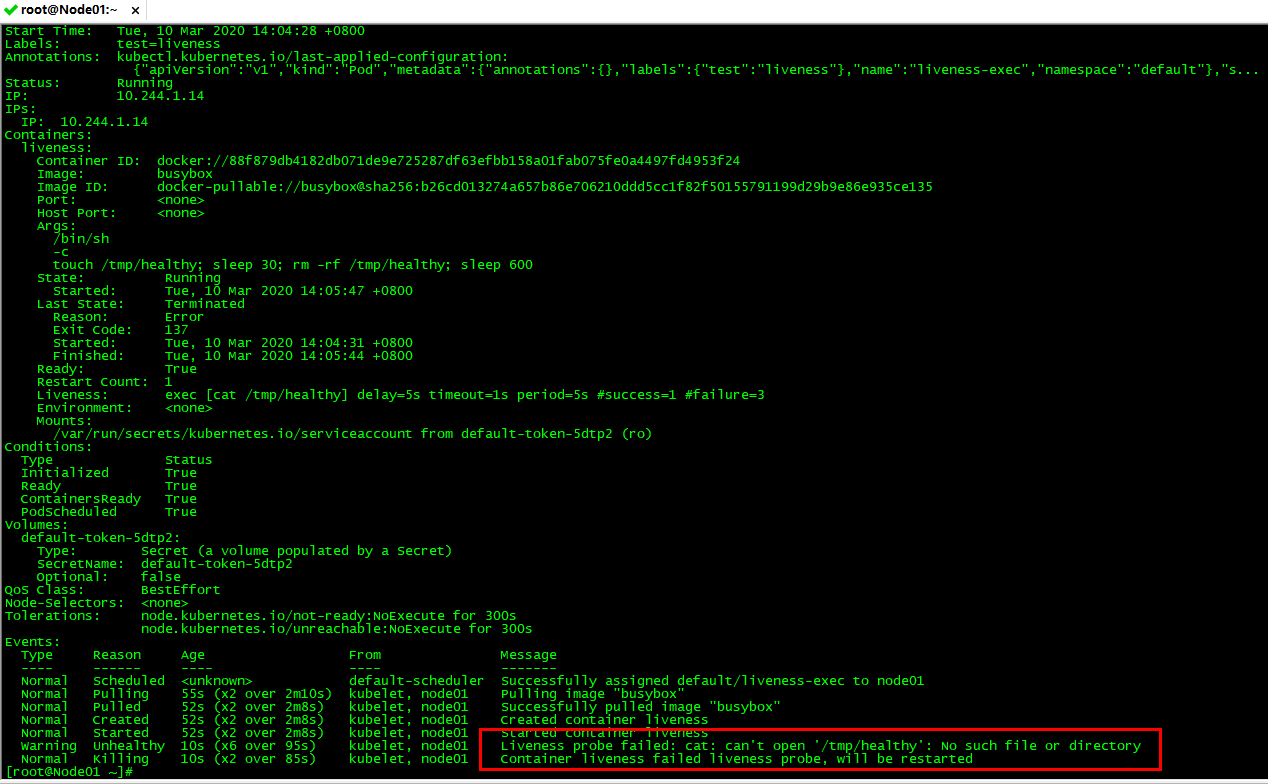
我们可以看到容器是正常启动的,40s后,再查看下 Pod 的 Event ,在最下⾯有⼀条信息显示 liveness probe 失败了,容器被删掉并重新创建。然后通过 kubectl get pod liveness-exec 可以看到 RESTARTS 值加1了。我们可以看到、文件删除以后就被livenessProbe存活探针捕捉到了。
通过HTTP监测livenessProbe
当然,我们也可以采用HTTP的方式来监测livenessProbe,我们同样创建一个示例文件:
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness-http
spec:
containers:
- name: liveness
image: cnych/liveness
args:
- /server
livenessProbe:
httpGet:
path: /healthz
port: 8080
httpHeaders:
- name: X-Custom-Header
value: Awesome
initialDelaySeconds: 3
periodSeconds: 3
注:根据 periodSeconds 属性我们可以知道 kubelet 需要每隔3秒执⾏⼀次 liveness probe ,该探针将向容器中的 server 的8080端⼝发送⼀个 HTTP GET 请求。如果 server 的 /healthz 路径的handler 返回⼀个成功的返回码,kubelet 就会认定该容器是活着的并且很健康,如果返回失败的返回码, kubelet 将杀掉该容器并重启。 initialDelaySeconds 指定 kubelet 在该执⾏第⼀次探测之前需要等待3秒钟。
通常来说,任何⼤于200小于400的返回码都会认定是成功的返回码。其他返回码都会被认为是失败的返回码。我们可以先来查看看上面代码中 healthz 的实现过程:
http.HandleFunc("/healthz", func(w http.ResponseWriter, r *http.Request) {
duration := time.Now().Sub(started)
if duration.Seconds() > 10 {
w.WriteHeader(500)
w.Write([]byte(fmt.Sprintf("error: %v", duration.Seconds())))
} else {
w.WriteHeader(200)
w.Write([]byte("ok"))
}
})
注:最开始前10s返回状态码200,10s过后就返回500的 status_code 了。所以当容器启动3秒后, kubelet 开始执⾏健康检查。第⼀次健康监测会成功,因为是在10s之内,但是10秒后,健康检查将失败,因为现在返回的是⼀个错误的状态码了,所以 kubelet 将会杀掉和重启容器。
同样的,我们来创建 Pod 并测试效果,我们发现10秒后查看 Pod 的 event,liveness probe 监测到失败并重启了容器:

3、可读性探针
通过tcpSocket监测Readiness Probe
然后我们通过端⼝的方式来配置存活探针,使⽤此配置 kubelet 将尝试在指定端⼝上打开容器的套接字。 如果可以建立连接,容器被认为是健康的,如果不能就认为是失败的:
apiVersion: v1
kind: Pod
metadata:
name: goproxy
labels:
app: goproxy
spec:
containers:
- name: goproxy
image: cnych/goproxy
ports:
- containerPort: 8080
readinessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 5
periodSeconds: 10
livenessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 15
periodSeconds: 20
注:TCP 检查的配置与 HTTP 检查非常相似,只是将 httpGet 替换成了 tcpSocket 。 而且我们同时使⽤了 readiness probe 和 liveness probe 两种探针。 容器启动后5秒后, kubelet 将发送第⼀个 readiness probe (可读性探针)。 该探针会去连接容器的8080端,如果连接成功,则该Pod 将被标记为就绪状态。然后 Kubelet 将每隔10秒钟执⾏⼀次该检查。
除了 readiness probe 之外,该配置还包括 liveness probe 。 容器启动15秒后, kubelet 将运⾏第⼀个 liveness probe 。 就像 readiness probe ⼀样,这将尝试去连接到容器的8080端⼝。如果 liveness probe 失败,容器将重新启动。
有的时候,应⽤程序可能暂时⽆法对外提供服务,例如,应⽤程序可能需要在启动期间加载⼤量数据或配置⽂件。 在这种情况下,您不想杀死应⽤程序,也不想对外提供服务。 那么这个时候我们就可以使⽤ readiness probe 来检测和减轻这些情况。 Pod中的容器可以报告⾃⼰还没有准备,不能处理Kubernetes服务发送过来的流量。
从上⾯的 YAML ⽂件我们可以看出 readiness probe 的配置跟 liveness probe 很像,基本上是⼀致的。唯⼀的不同是使用 readinessProbe 而不是 livenessProbe 。两者如果同时使用的话就可以确保流量不会到达还未准备好的容器,准备好过后,如果应⽤程序出现了错误,则会重新启动容器。

另外除了上⾯的 initialDelaySeconds 和 periodSeconds 属性外,探针还可以配置如下⼏个参数:
- timeoutSeconds:探测超时时间,默认1秒,最小1秒。
- successThreshold:探测失败后,最少连续探测成功多少次才被认定为成功。默认是 1,但是如果是
liveness则必须是 1。最小值是 1。 - failureThreshold:探测成功后,最少连续探测失败多少次才被认定为失败。默认是 3最小值是1。
以上就是 liveness probe (存活探针)和 readiness probe (可读性探针)的使⽤方法。